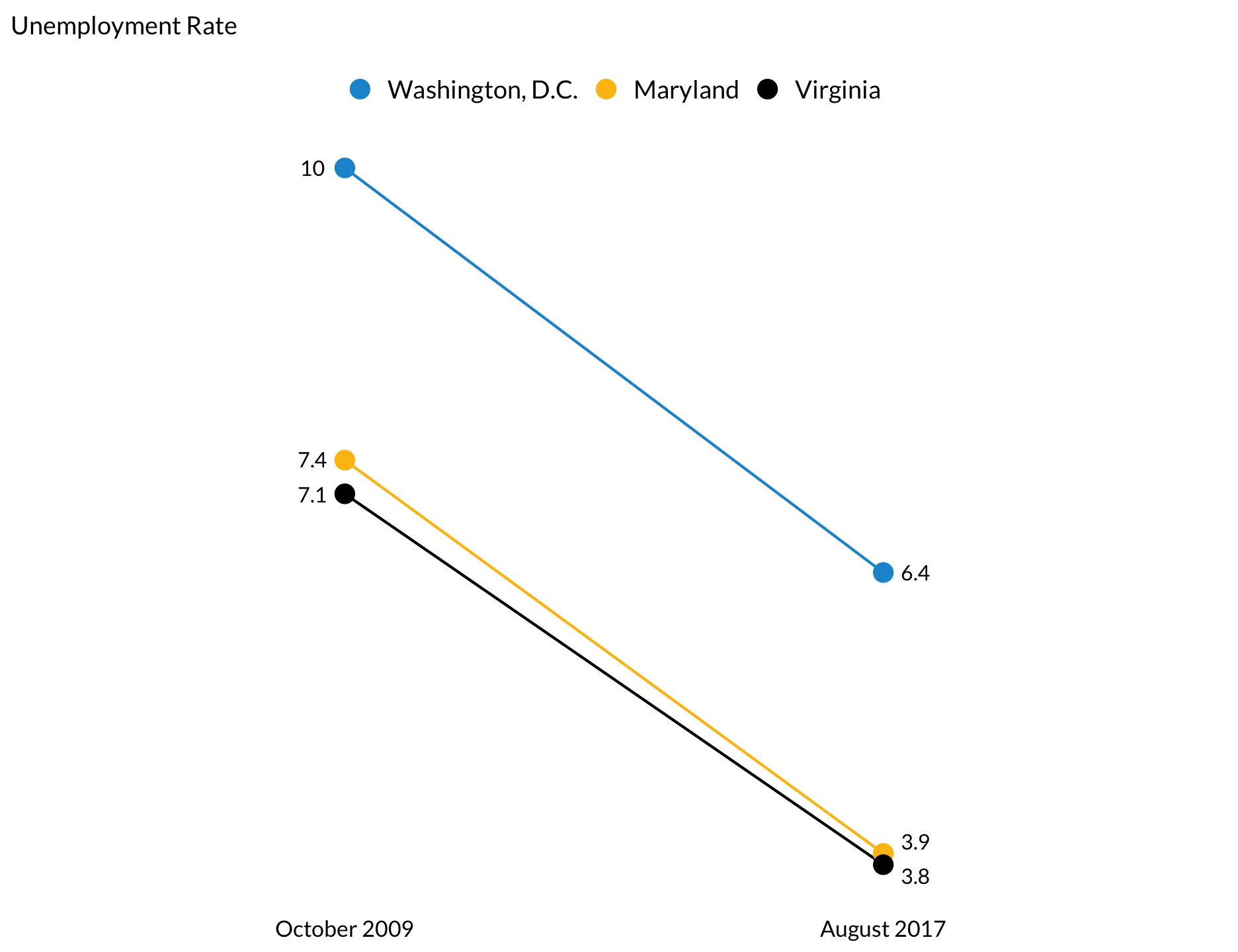
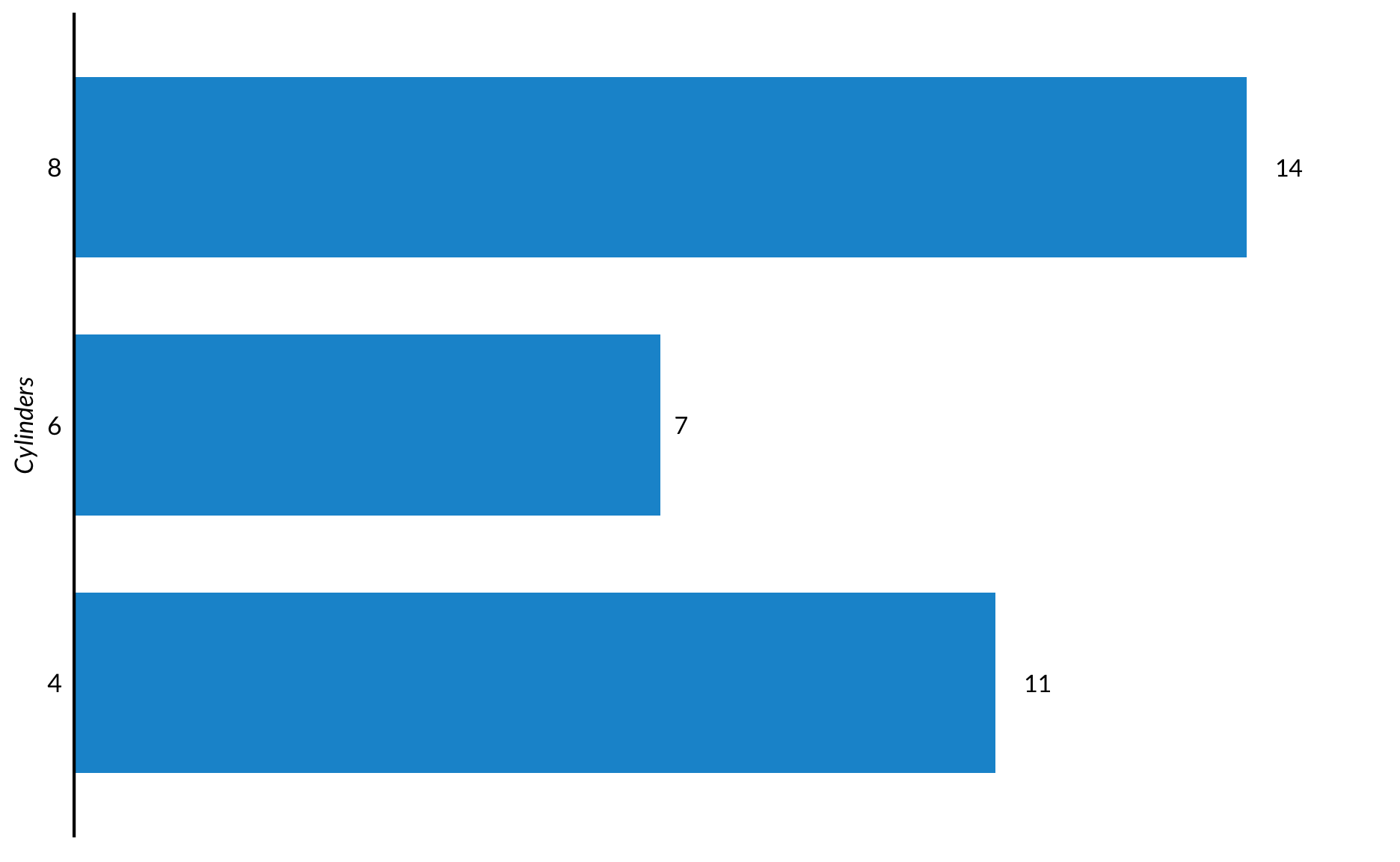R is a powerful, open-source programming language and environment. R excels at data management and munging, traditional statistical analysis, machine learning, and reproducible research, but it is probably best known for its graphics. This guide contains examples and instructions for popular and lesser-known plotting techniques in R. It also includes instructions for using urbnthemes, the Urban Institute’s R package for creating near-publication-ready plots with ggplot2. If you have any questions, please don’t hesitate to contact Aaron Williams (awilliams@urban.org) or Kyle Ueyama (kueyama@urban.org).
Background
library(urbnthemes) makes ggplot2 output align more closely with the Urban Institute’s Data Visualization style guide. This package does not produce publication ready graphics. Visual styles must still be edited using your project/paper’s normal editing workflow.
Exporting charts as a pdf will allow them to be more easily edited. See the Saving Plots section for more information.
The theme has been tested against ggplot2 version 3.0.0. It will not function properly with older versions of ggplot2
Using library(urbnthemes)
Run the following code to install or update urbnthemes:
Your Urban computer may not have the Lato font installed. If it is not installed, please install the free Lato font from Google. Below are step by step instructions:
For each .ttf file in the unzipped Lato/ folder, double click the file and click Install (on Windows) or Install Font (on Mac).
Import and register Lato into R by running urbnthemes::lato_import() in the console once. Be patient as this may take a few minutes!
To confirm installation, run urbnthemes::lato_test(). If this is successful you’re done and Lato will automatically be used when creating plots with library(urbnthemes). You only need to install Lato once per computer.
Waffle charts with glyphs require fontawesome. fontawesome_test() and fontawesome_install() are the fontawesome versions of the above functions. Be sure to install fontawesome from here first.
Grammar of Graphics and Conventions
Hadley Wickham’s ggplot2 is based on Leland Wilkinson’s The Grammar of Graphics and Wickham’s A Layered Grammar of Graphics. The layered grammar of graphics is a structured way of thinking about the components of a plot, which then lend themselves to the simple structure of ggplot2.
Data are what are visualizaed in a plot and mappings are directions for how data are mapped in a plot in a way that can be perceived by humans.
Geoms are representations of the actual data like points, lines, and bars.
Stats are statistical transformations that represent summaries of the data like histograms.
Scales map values in the data space to values in the aesthetic space. Scales draw legends and axes.
Coordinate Systems describe how geoms are mapped to the plane of the graphic.
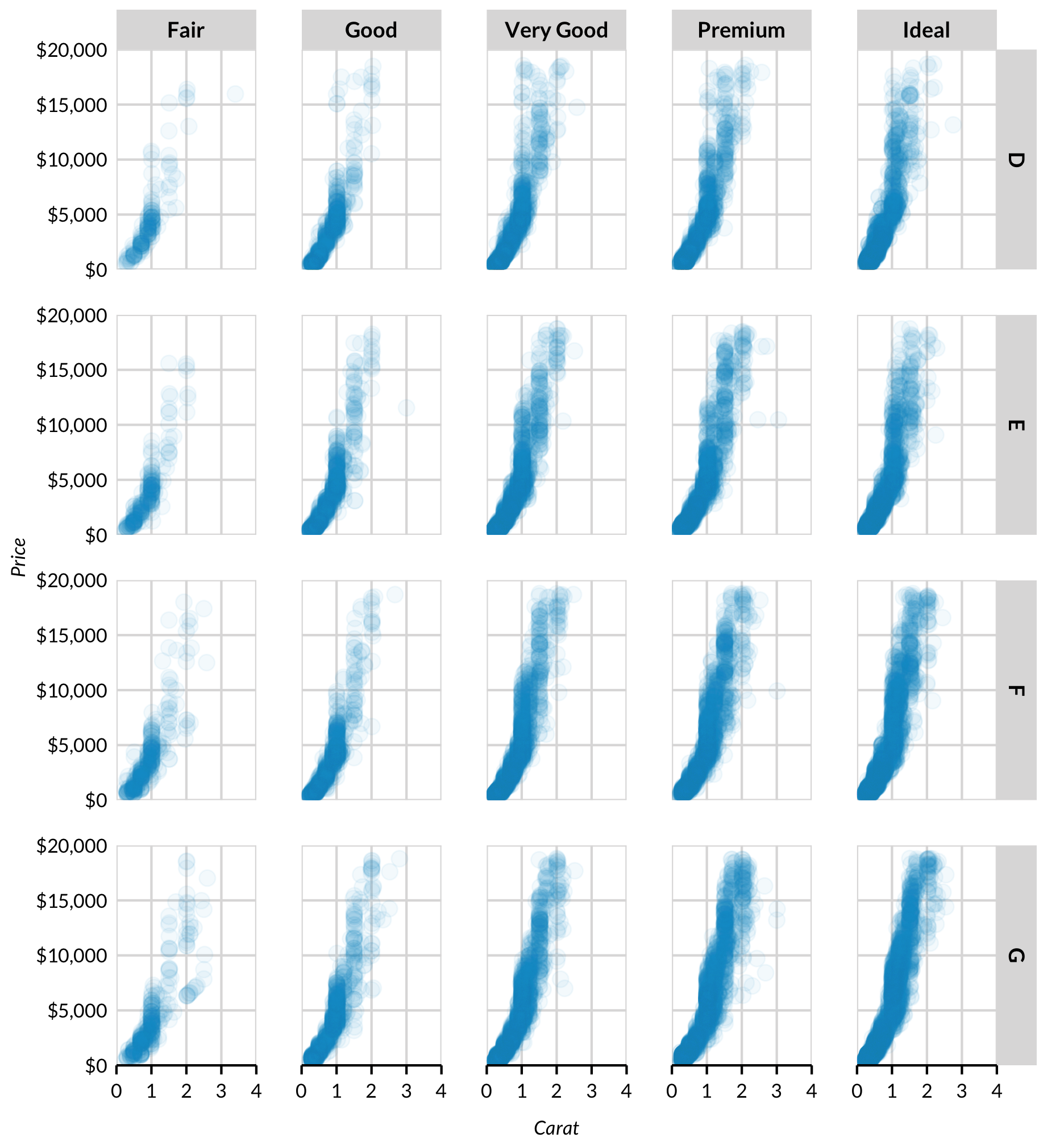
Facets break the data into meaningful subsets like small multiples.
Themes control the finer points of a plot such as fonts, font sizes, and background colors.
ggplot2 expects data to be in data frames or tibbles. It is preferable for the data frames to be “tidy” with each variable as a column, each obseravtion as a row, and each observational unit as a separate table. dplyr and tidyr contain concise and effective tools for “tidying” data.
R allows function arguments to be called explicitly by name and implicitly by position. The coding examples in this guide only contain named arguments for clarity.
Graphics will sometimes render differently on different operating systems. This is because anti-aliasing is activated in R on Mac and Linux but not activated in R on Windows. This won’t be an issue once graphics are saved.
Continuous x-axes have ticks. Discrete x-axes do not have ticks. Use remove_ticks() to remove ticks.
This example introduces coord_flip() and remove_axis(axis = "x", flip = TRUE). remove_axis() is from library(urbnthemes) and creates a custom theme for rotated bar plots.
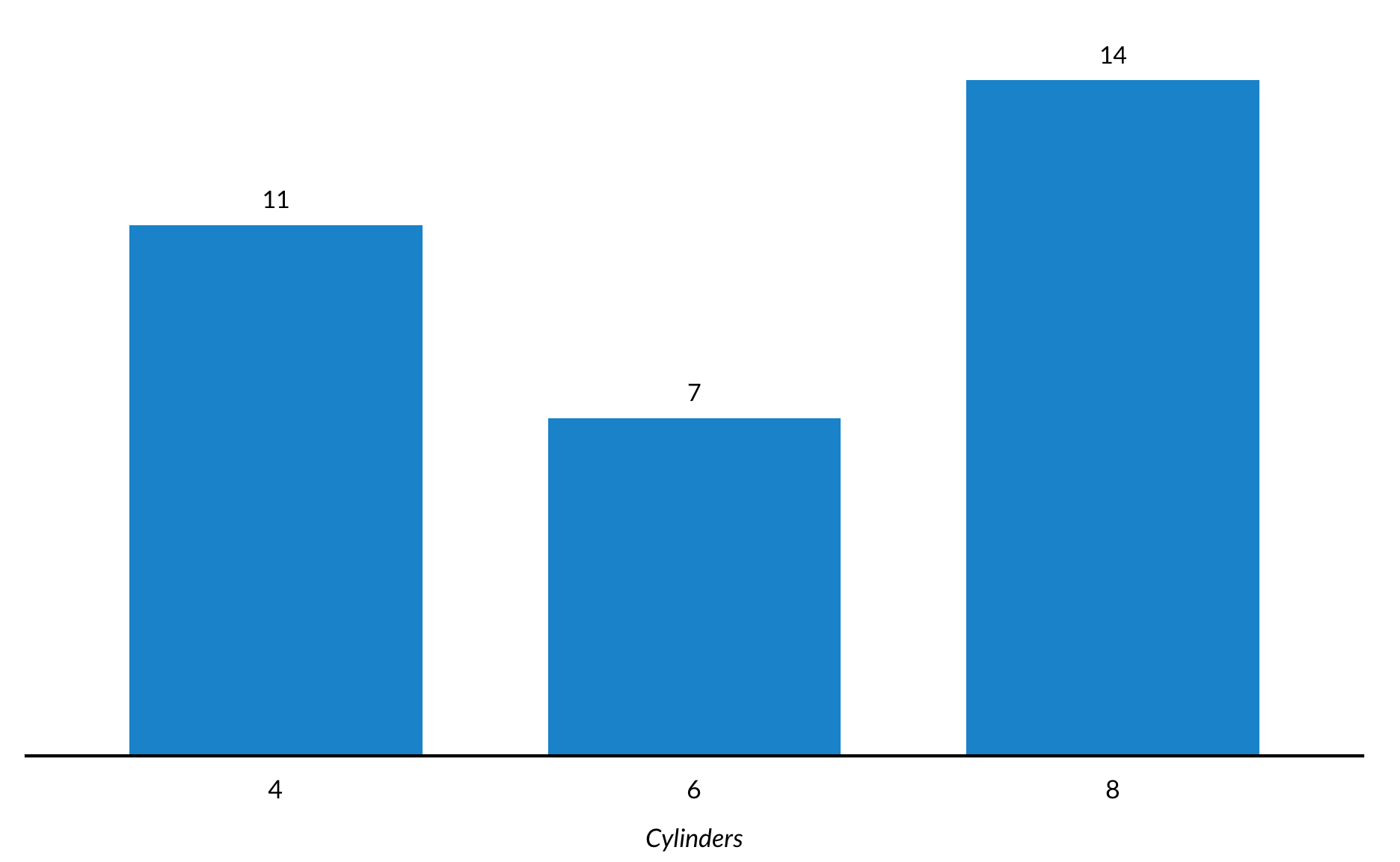
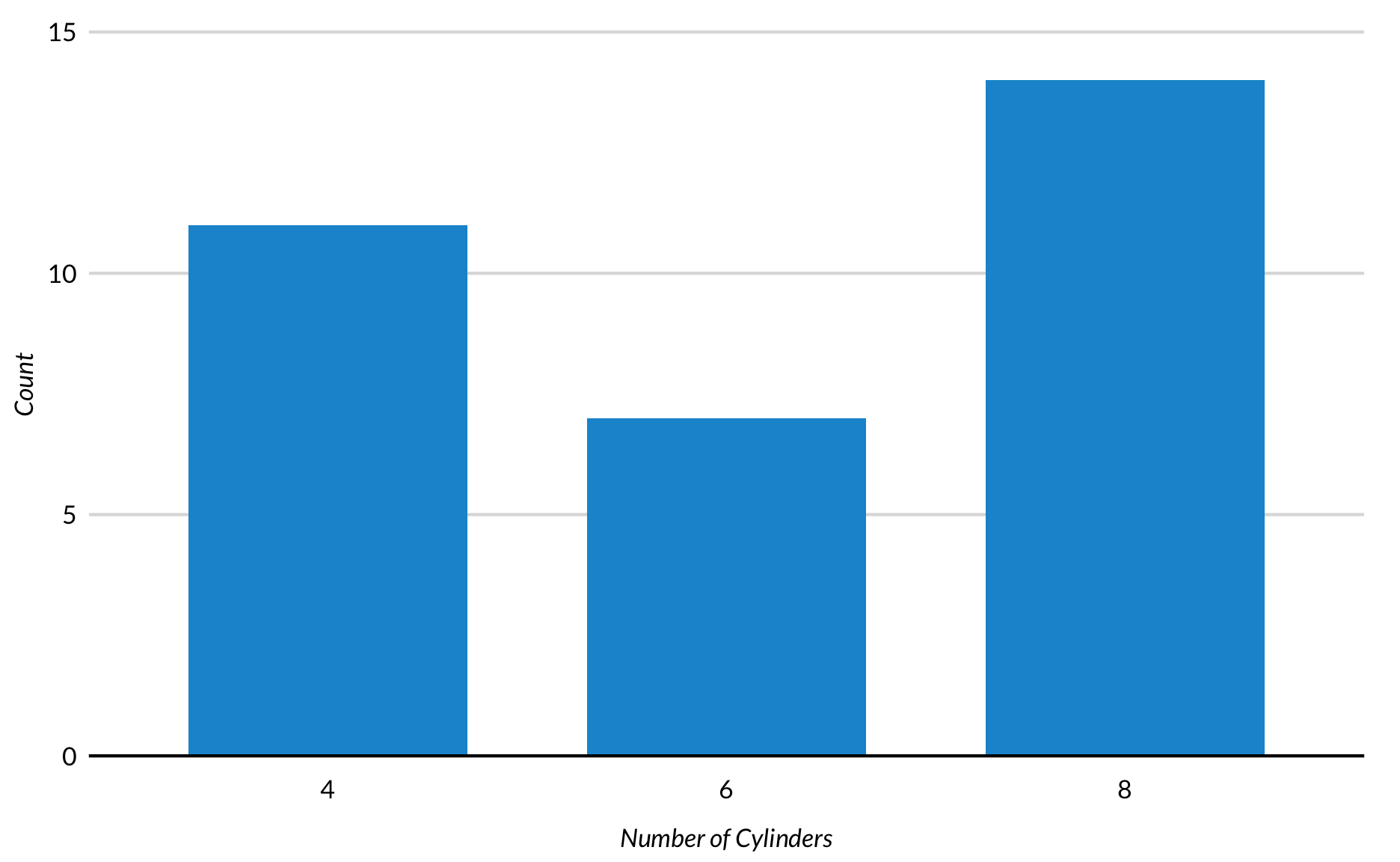
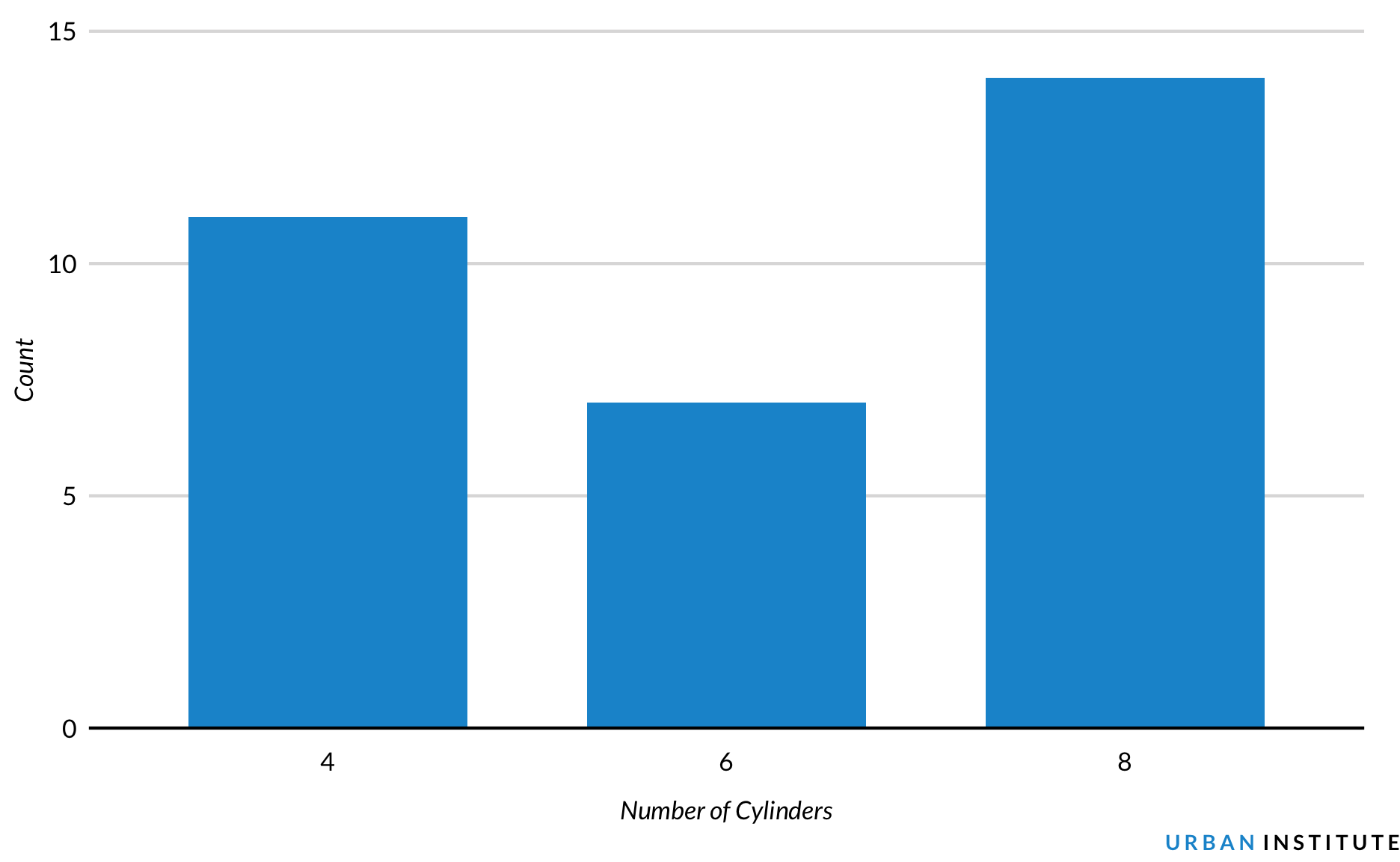
This is identical to the previous plot except colors and a legend are added with fill = cyl. Turning x into a factor with factor(cyl) skips 5 and 7 on the x-axis. Adding fill = cyl without factor() would have created a continuous color scheme and legend.
mtcars %>%mutate(cyl =factor(cyl)) %>%count(cyl) %>%ggplot(mapping =aes(x = cyl, y = n, fill = cyl)) +geom_col() +geom_text(mapping =aes(label = n), vjust =-1) +scale_y_continuous(expand =expansion(mult =c(0, 0.1))) +labs(x ="Cylinders",y =NULL) +remove_ticks() +remove_axis()
Stacked Bar Plot
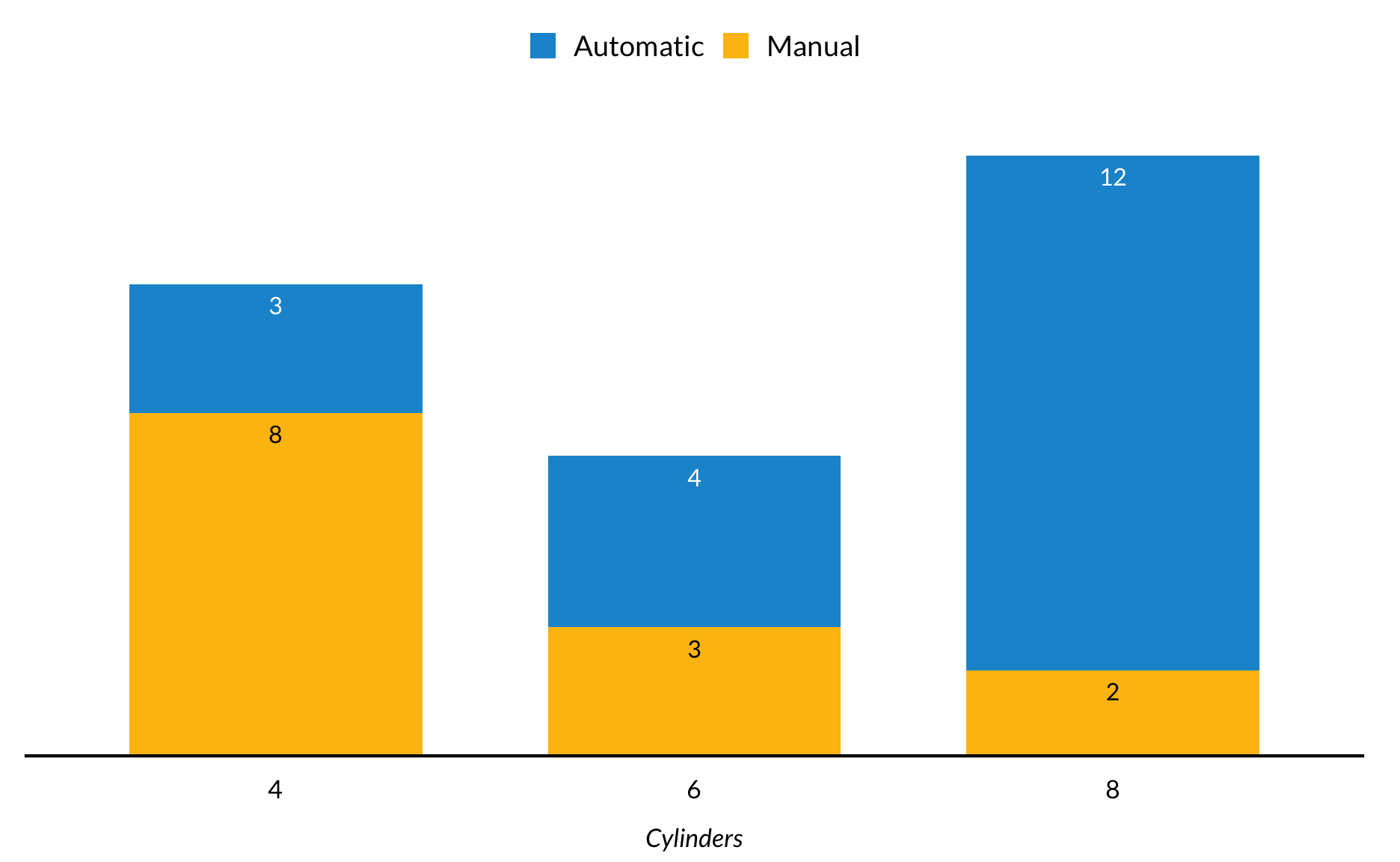
An additional aesthetic can easily be added to bar plots by adding fill = categorical variable to the mapping. Here, transmission type subsets each bar showing the count of cars with different numbers of cylinders.
mtcars %>%mutate(am =factor(am, labels =c("Automatic", "Manual")),cyl =factor(cyl)) %>%group_by(am) %>%count(cyl) %>%group_by(cyl) %>%arrange(desc(am)) %>%mutate(label_height =cumsum(n)) %>%ggplot() +geom_col(mapping =aes(x = cyl, y = n, fill = am)) +geom_text(aes(x = cyl, y = label_height -0.5, label = n, color = am)) +scale_color_manual(values =c("white", "black")) +scale_y_continuous(expand =expansion(mult =c(0, 0.1))) +labs(x ="Cylinders",y =NULL) +remove_ticks() +remove_axis() +guides(color ="none")
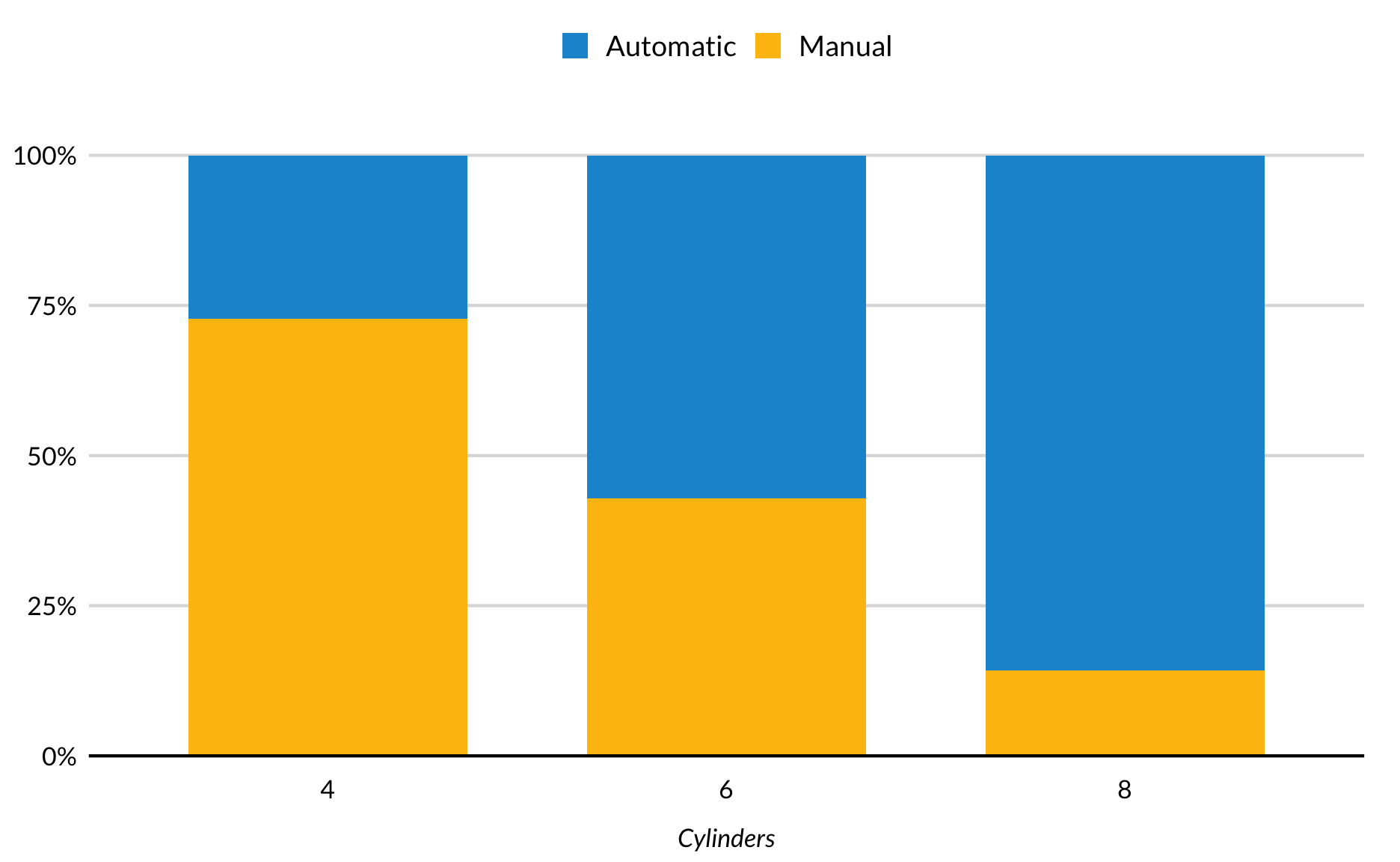
Stacked Bar Plot With Position = Fill
The previous examples used geom_col(), which takes a y value for bar height. This example uses geom_bar() which sums the values and generates a value for bar heights. In this example, position = "fill" in geom_bar() changes the y-axis from count to the proportion of each bar.
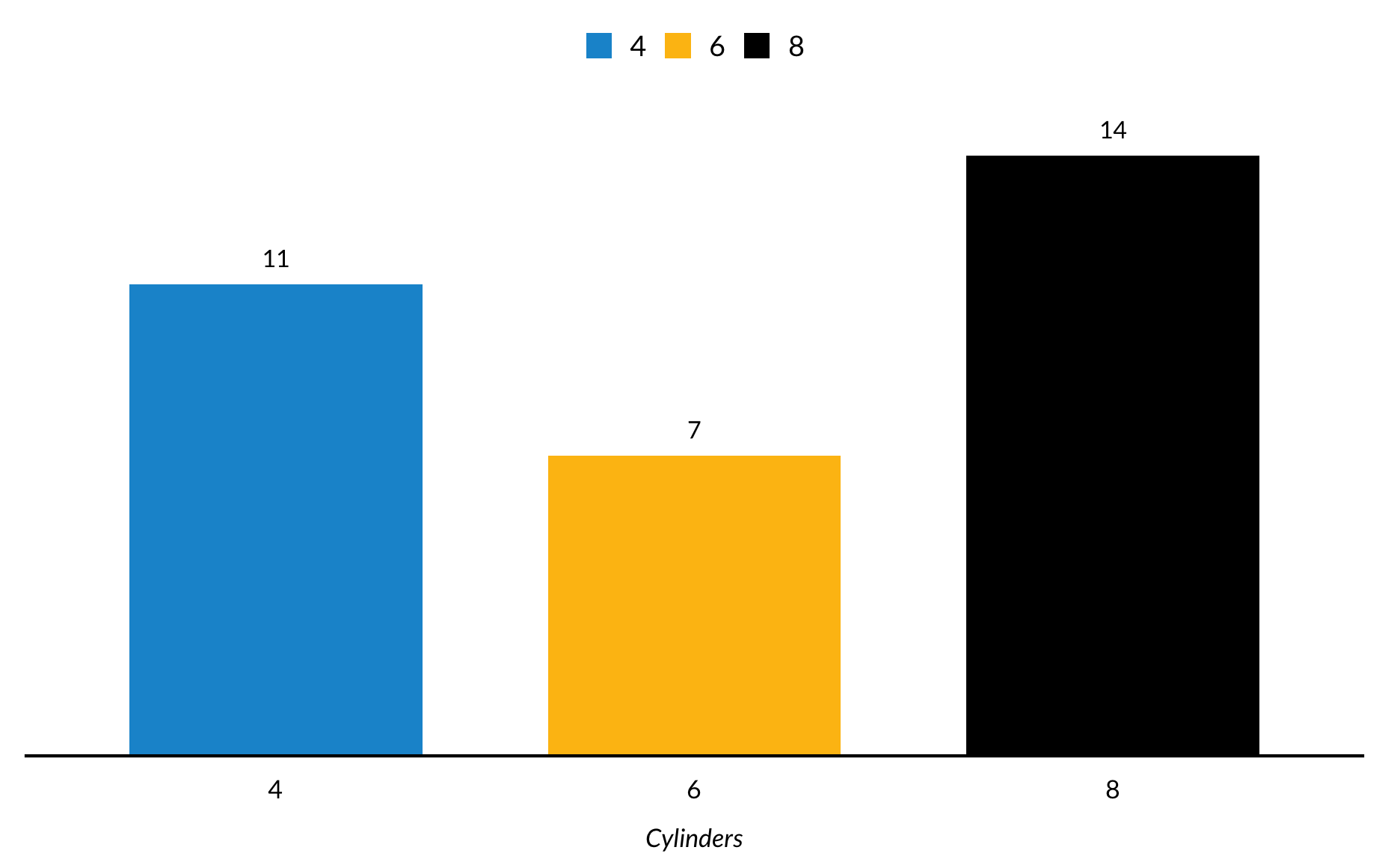
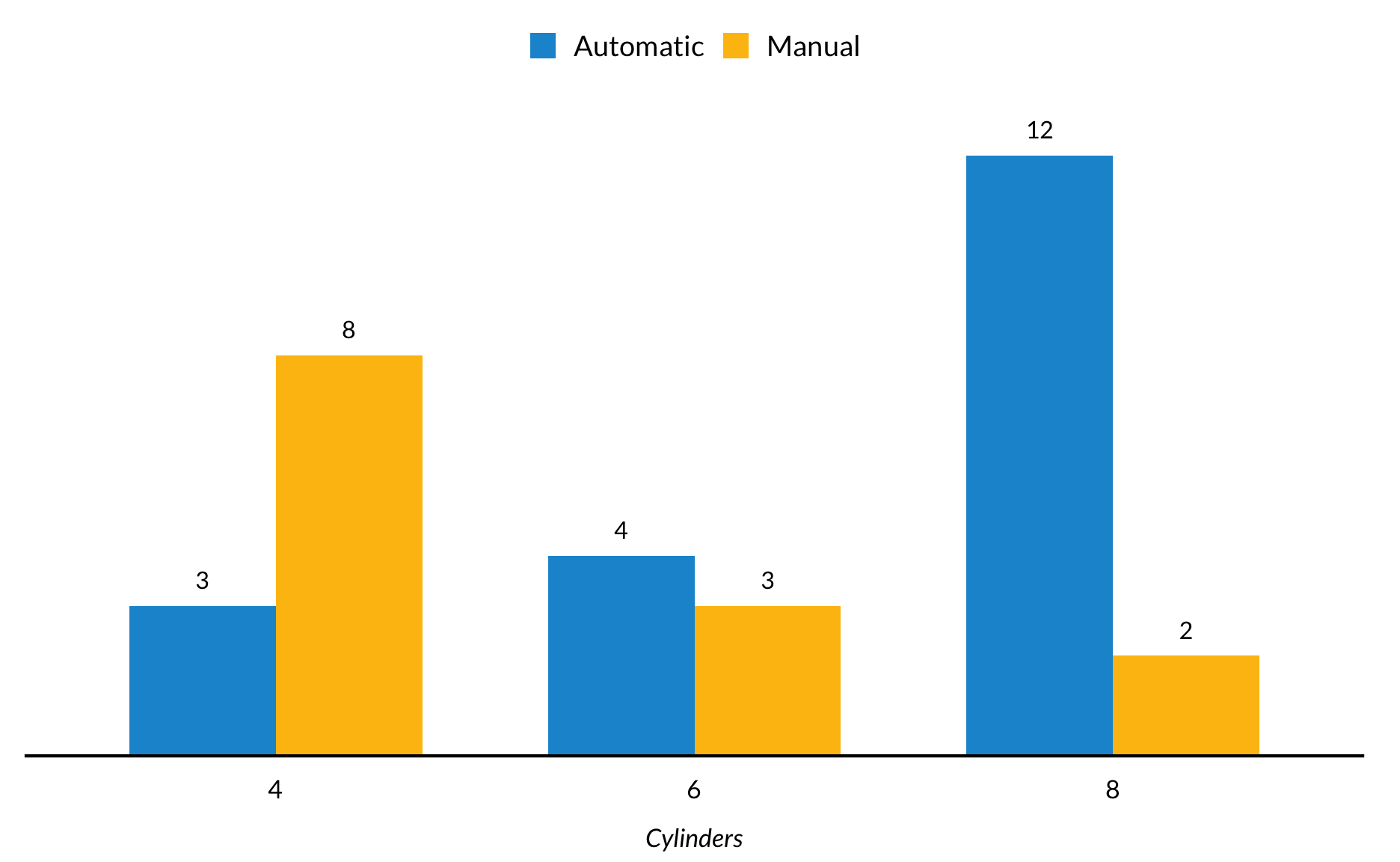
Subsetted bar charts in ggplot2 are stacked by default. position = "dodge" in geom_col() expands the bar chart so the bars appear next to each other.
mtcars %>%mutate(am =factor(am, labels =c("Automatic", "Manual")),cyl =factor(cyl)) %>%group_by(am) %>%count(cyl) %>%ggplot(mapping =aes(cyl, y = n, fill =factor(am))) +geom_col(position ="dodge") +geom_text(aes(label = n), position =position_dodge(width =0.7), vjust =-1) +scale_y_continuous(expand =expansion(mult =c(0, 0.1))) +labs(x ="Cylinders",y =NULL) +remove_ticks() +remove_axis()
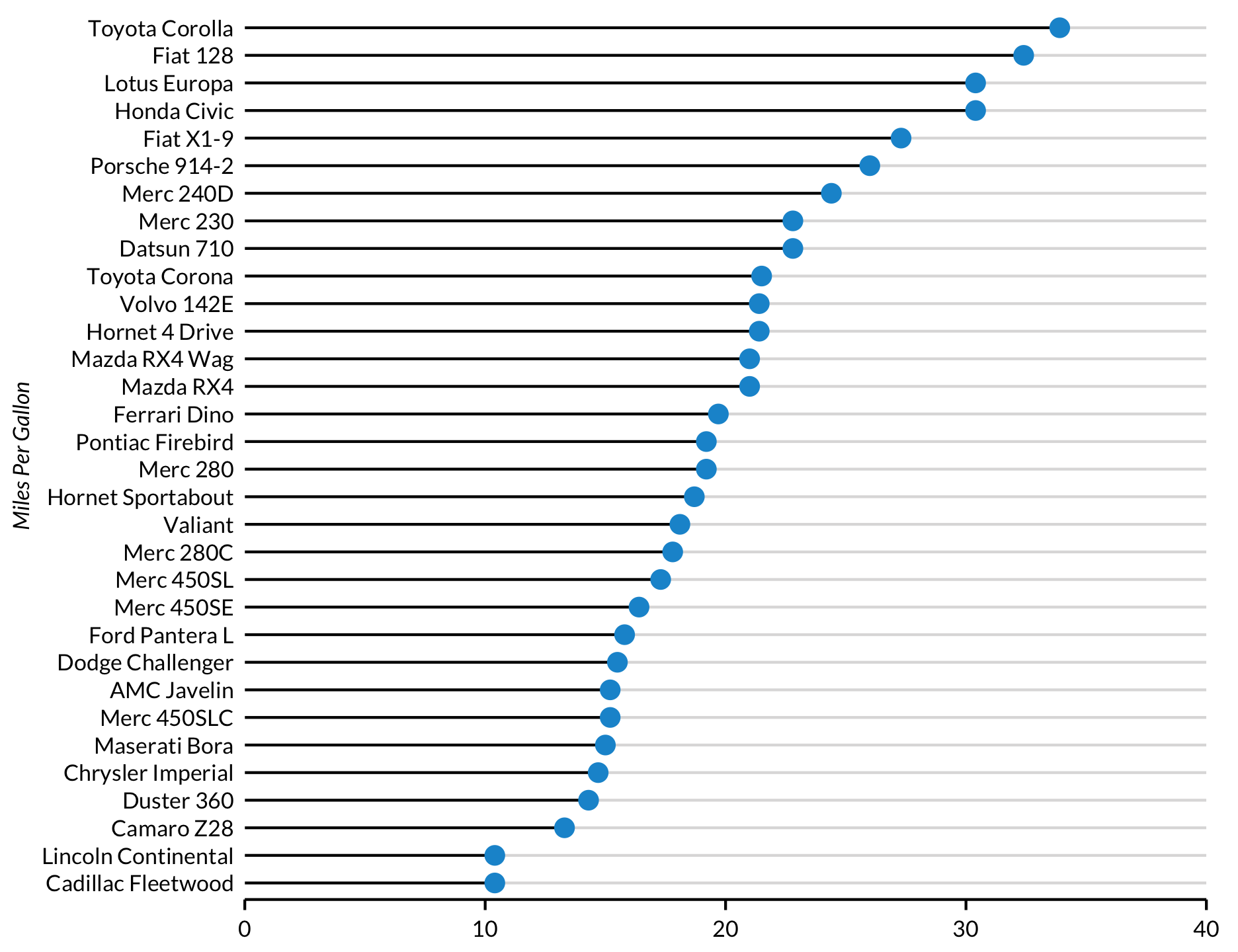
Lollipop plot/Cleveland dot plot
Lollipop plots and Cleveland dot plots are minimalist alternatives to bar plots. The key to both plots is to order the data based on the continuous variable using arrange() and then turn the discrete variable into a factor with the ordered levels of the continuous variable using mutate(). This step “stores” the order of the data.
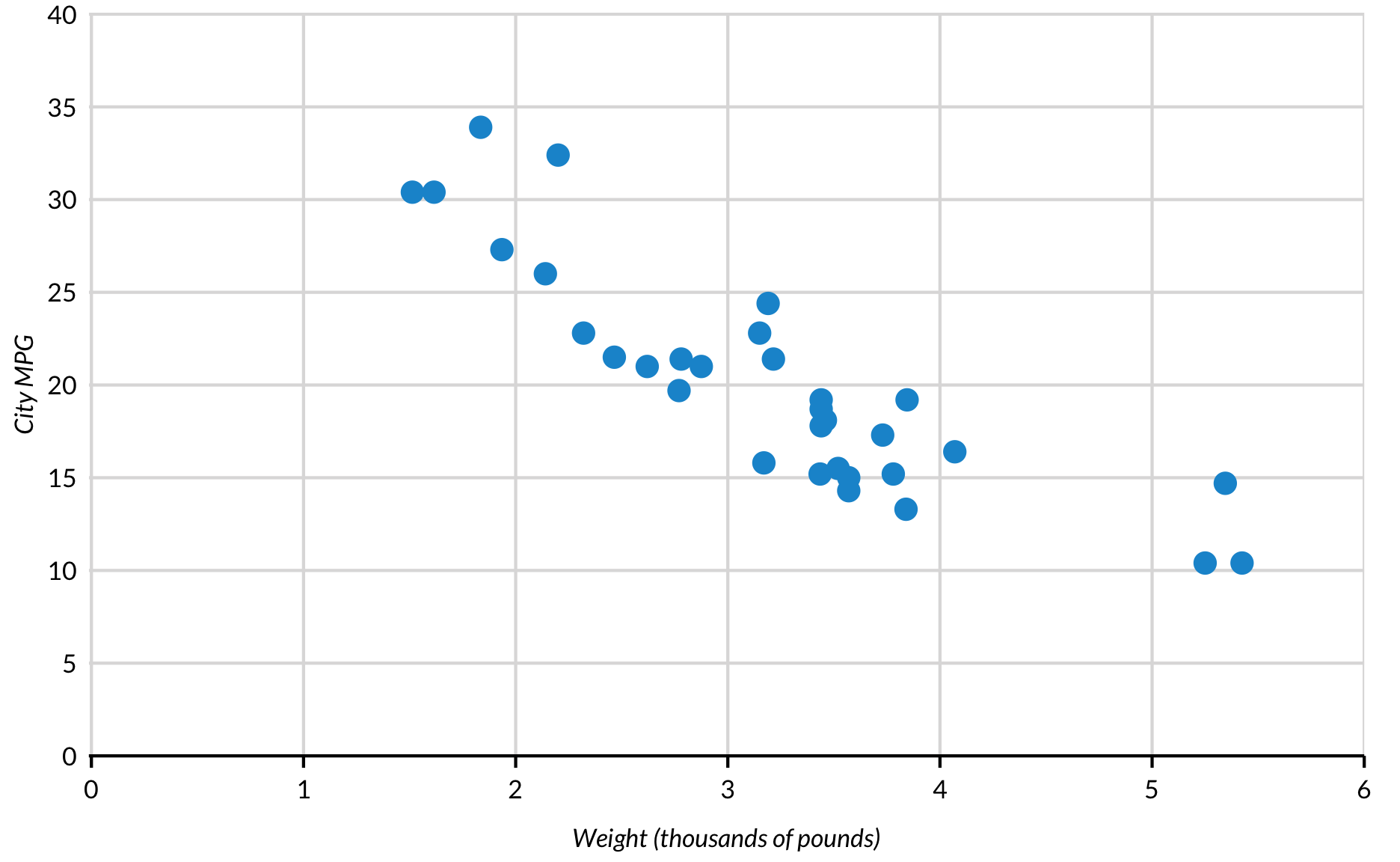
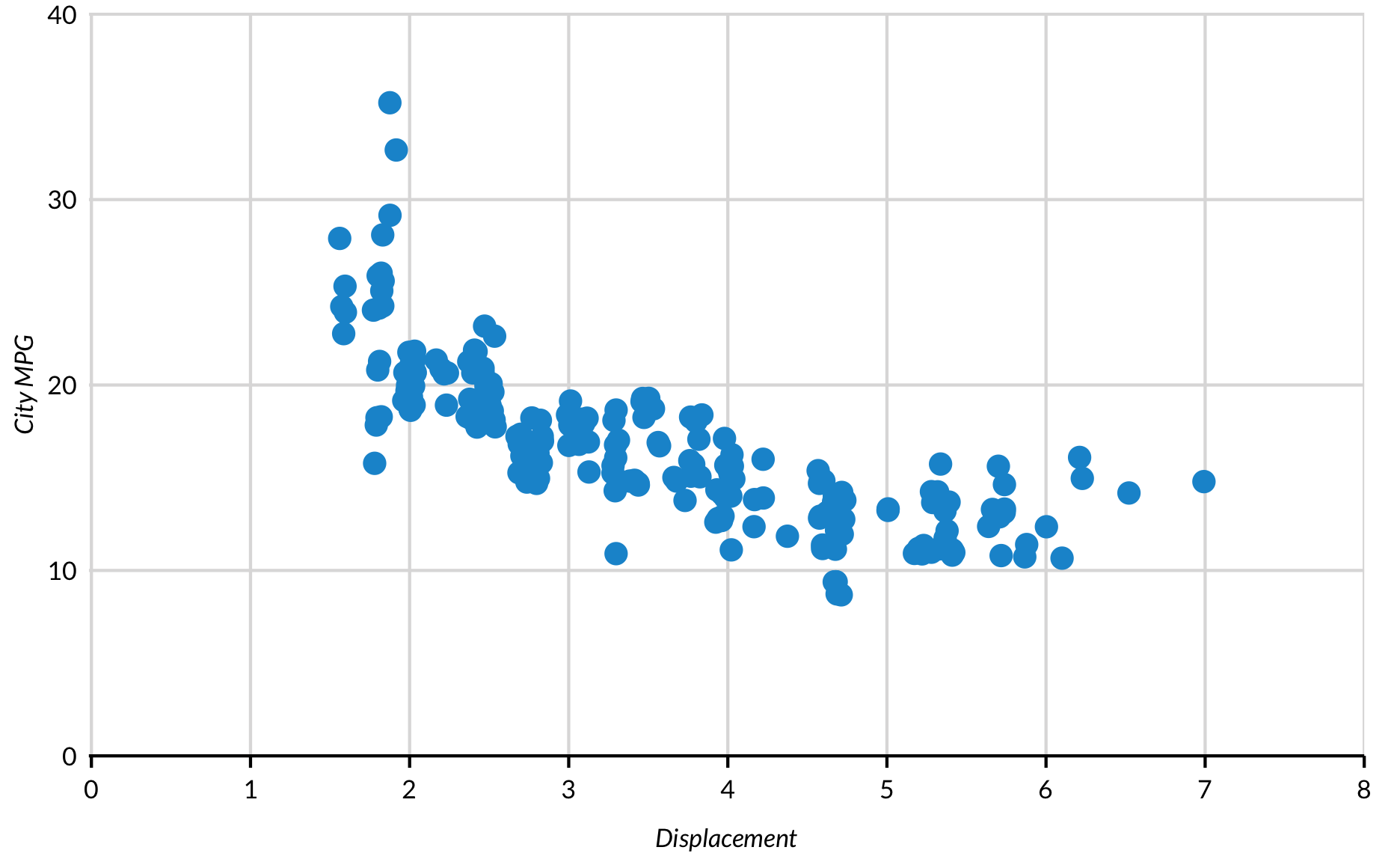
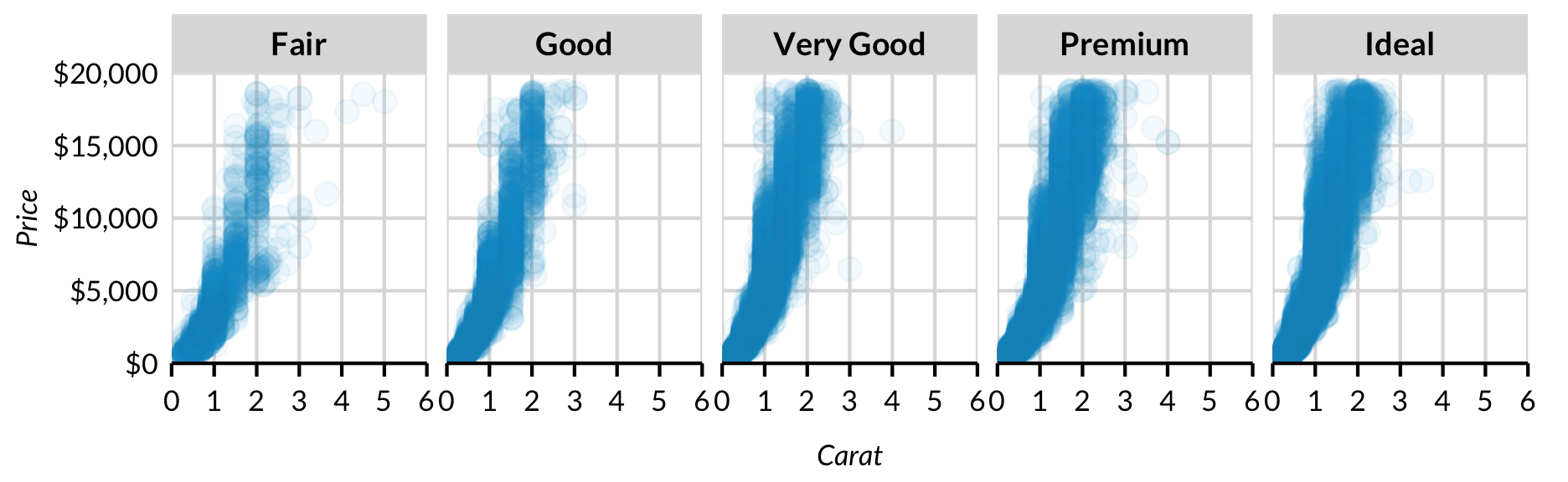
Scatter plots are useful for showing relationships between two or more variables. Use scatter_grid() from library(urbnthemes) to easily add vertical grid lines for scatter plots.
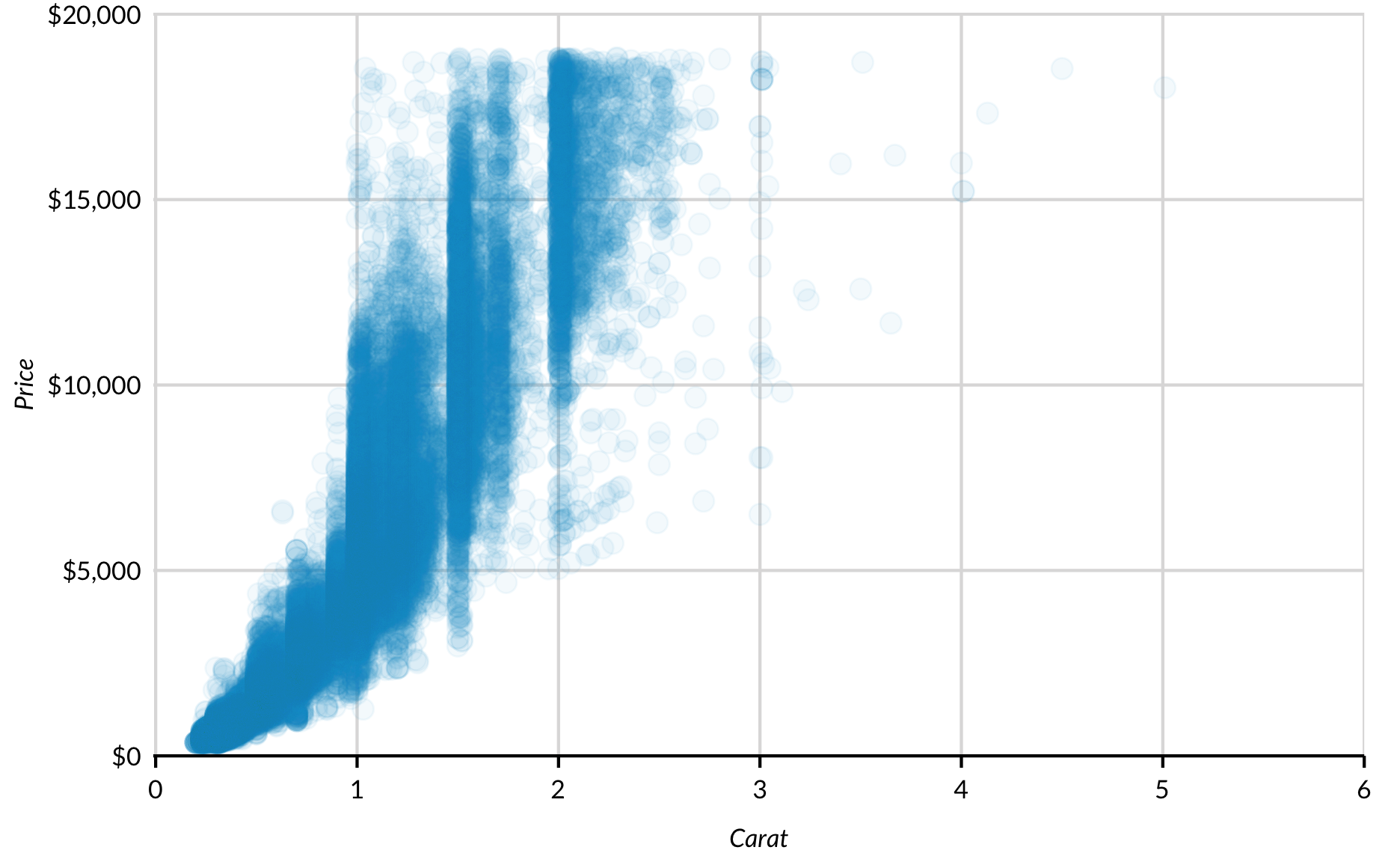
Large numbers of observations can sometimes make scatter plots tough to interpret because points overlap. Adding alpha = with a number between 0 and 1 adds transparency to points and clarity to plots. Now it’s easy to see that jewelry stores are probably rounding up but not rounding down carats!
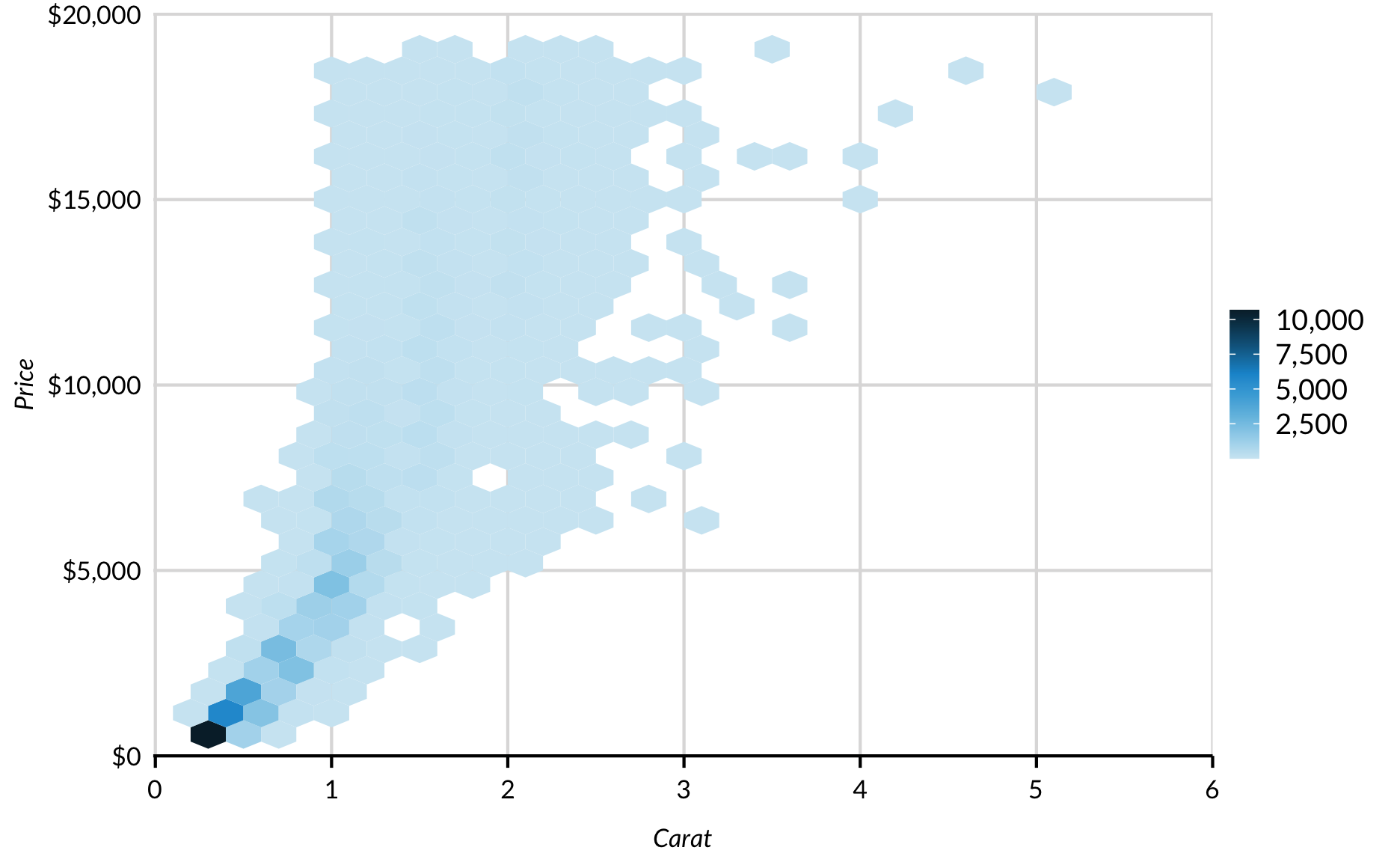
Sometimes transparency isn’t enough to bring clarity to a scatter plot with many observations. As n increases into the hundreds of thousands and even millions, geom_hex can be one of the best ways to display relationships between two variables.
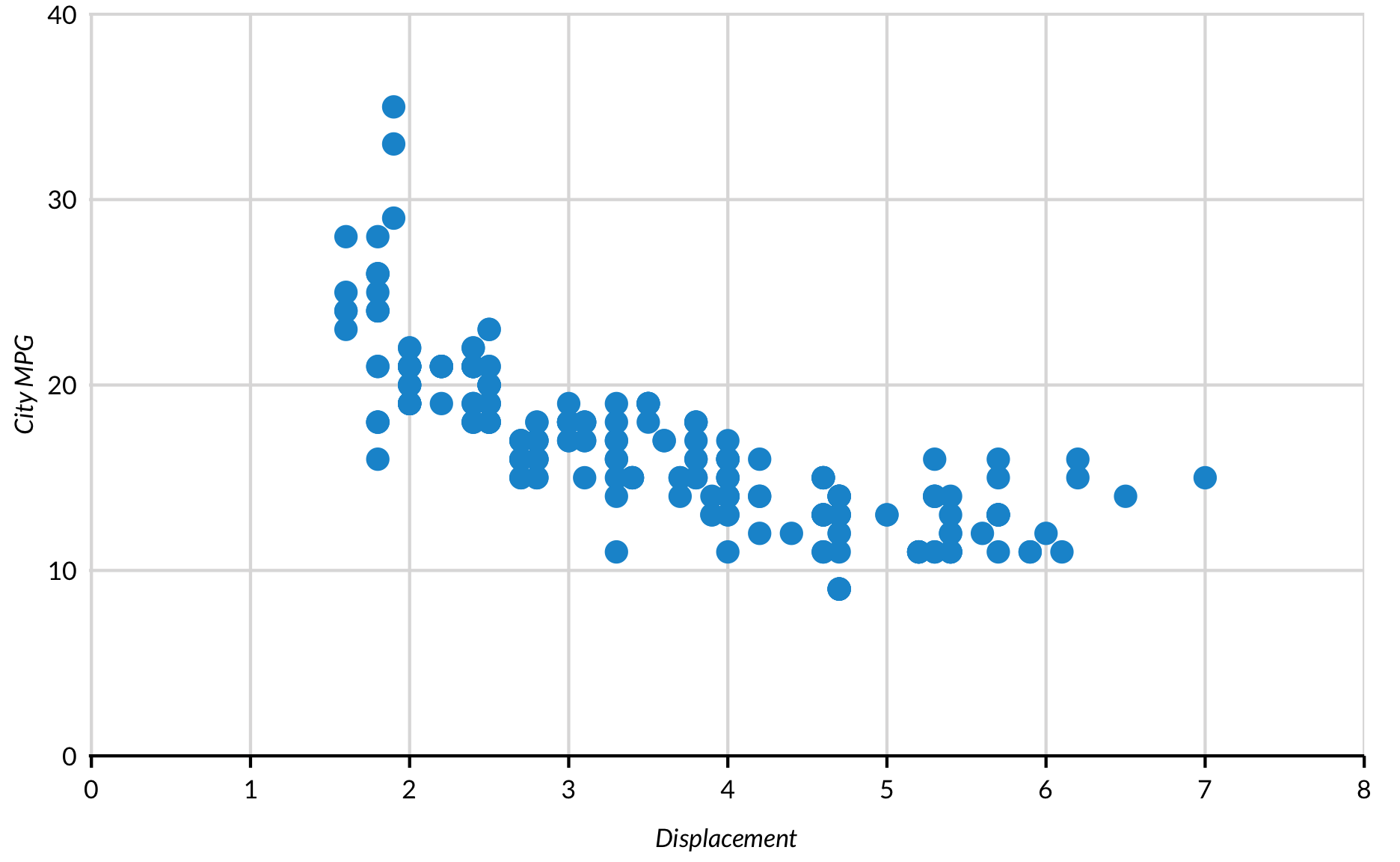
Sometimes scatter plots have many overlapping points but a reasonable number of observations. geom_jitter adds a small amount of random noise so points are less likely to overlap. width and height control the amount of noise that is added. In the following before-and-after, notice how many more points are visible after adding jitter.
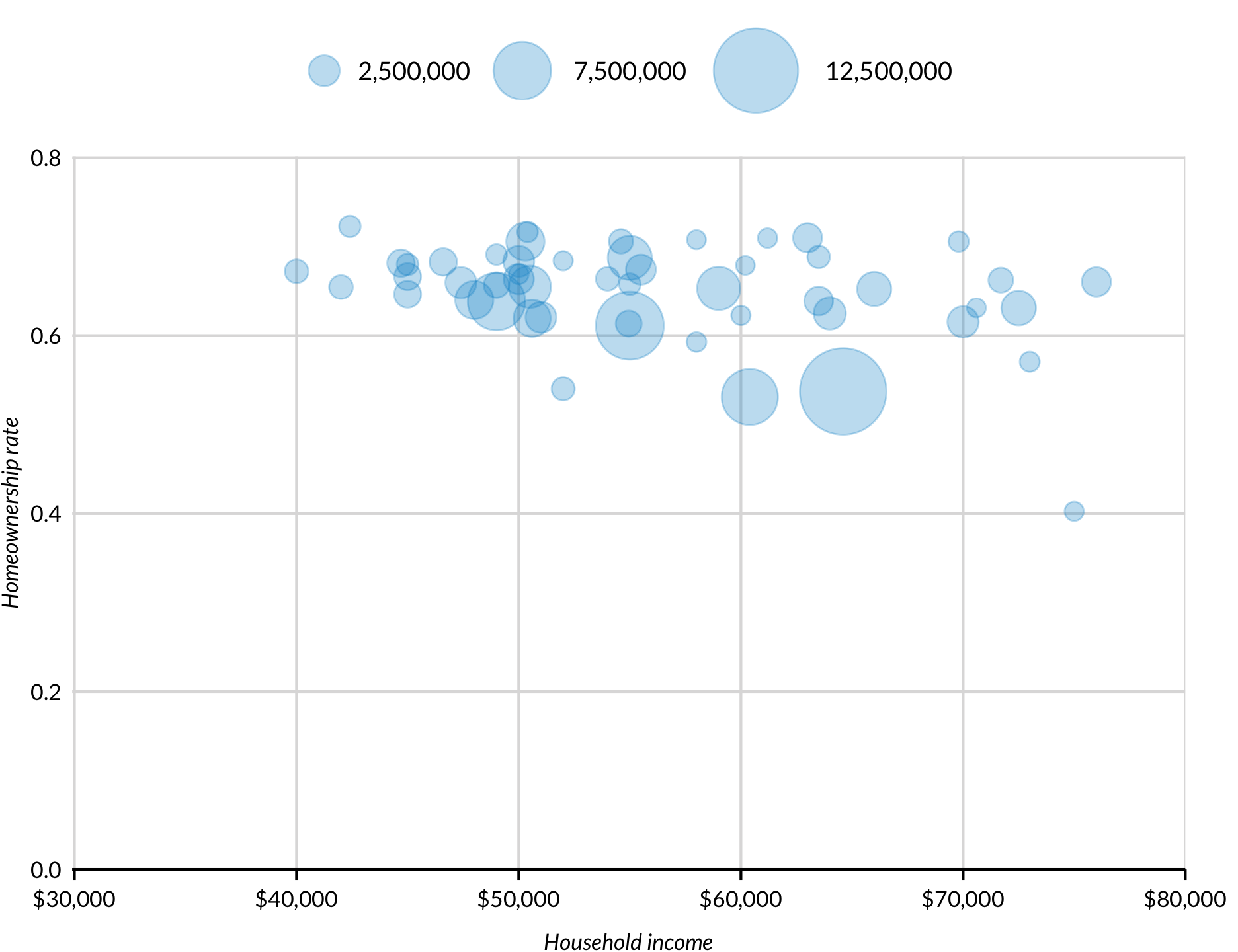
Weights and populations can be mapped in scatter plots to the size of the points. Here, the number of households in each state is mapped to the size of each point using aes(size = hhpop). Note: ggplot2::geom_point() is used instead of geom_point().
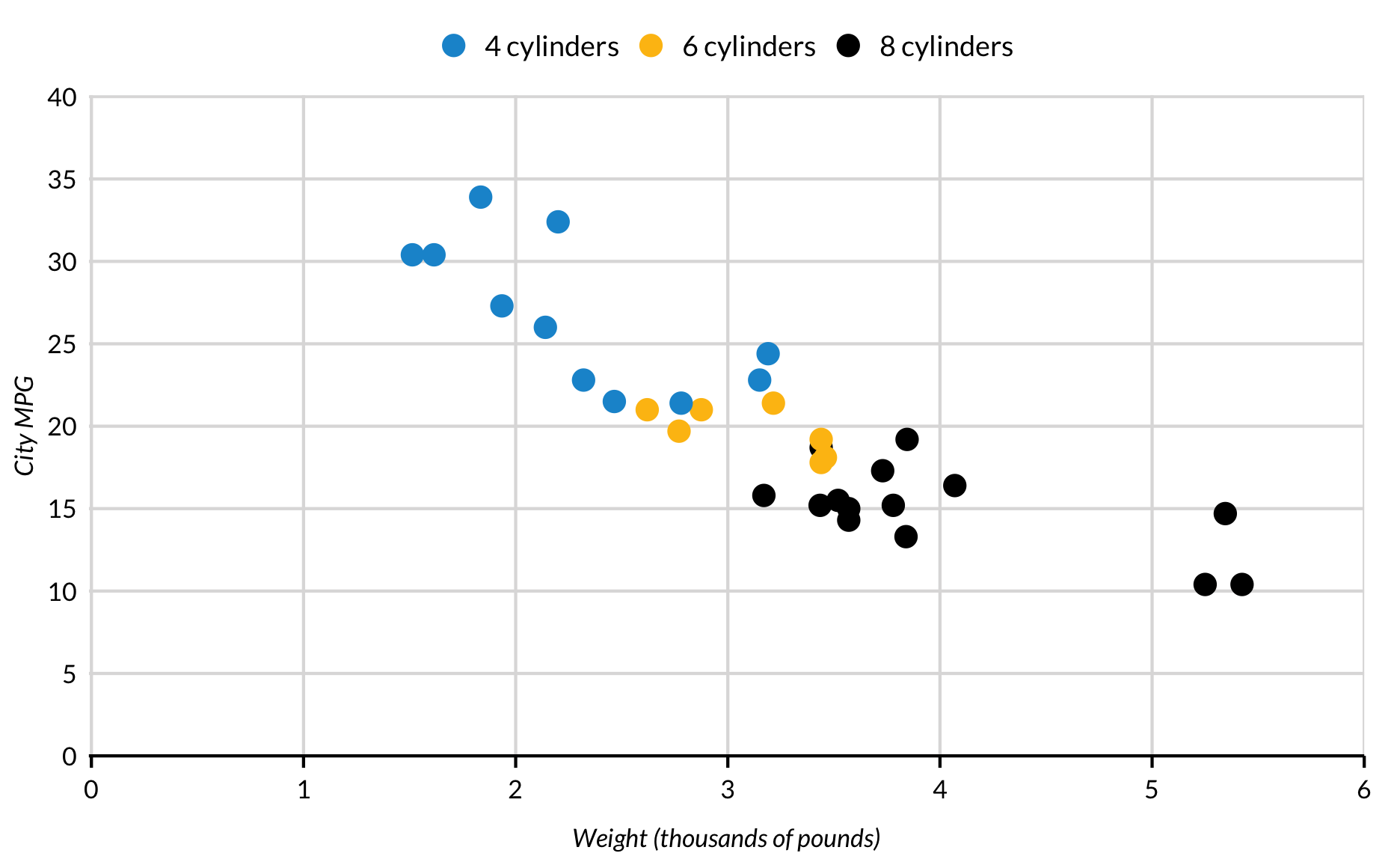
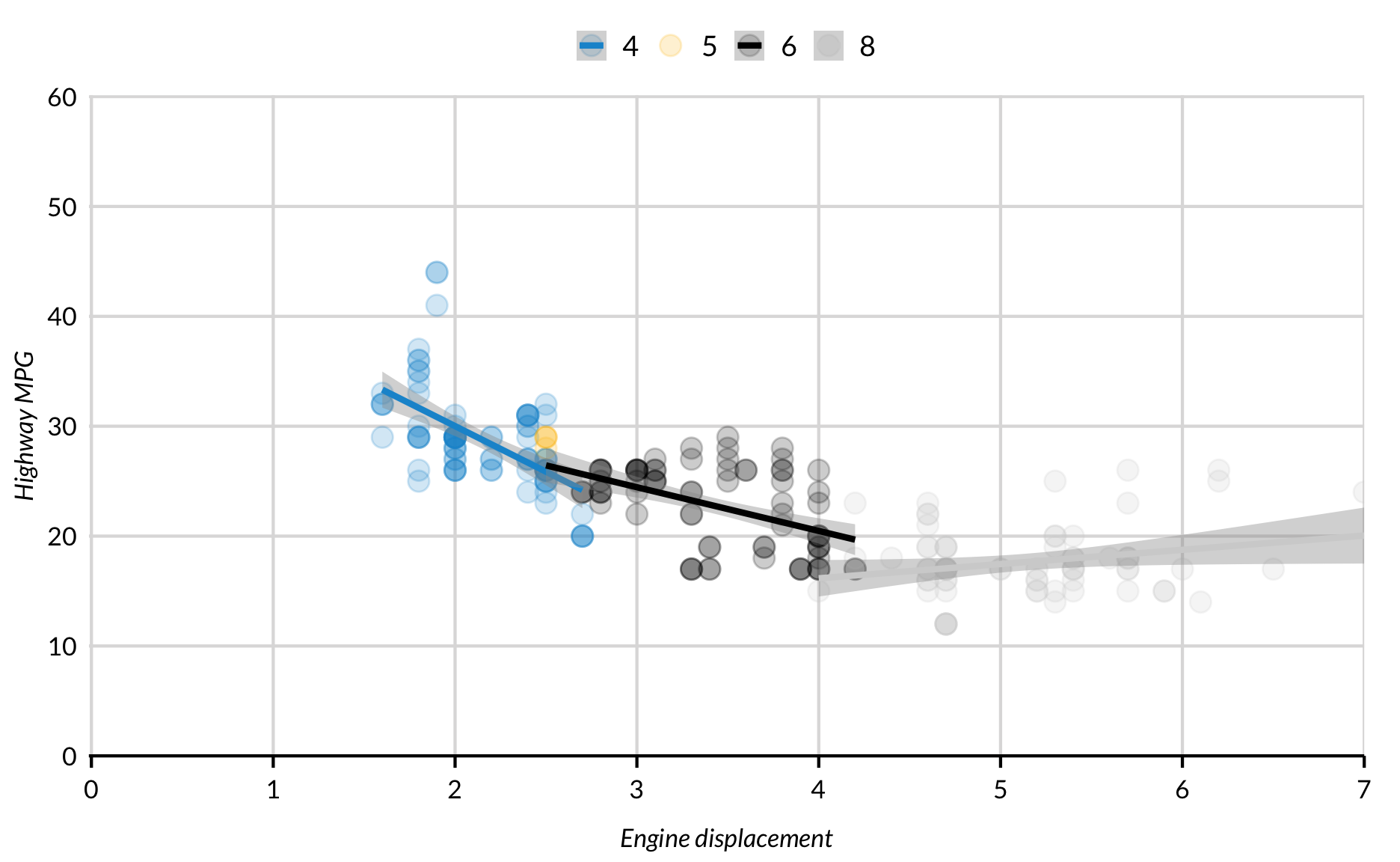
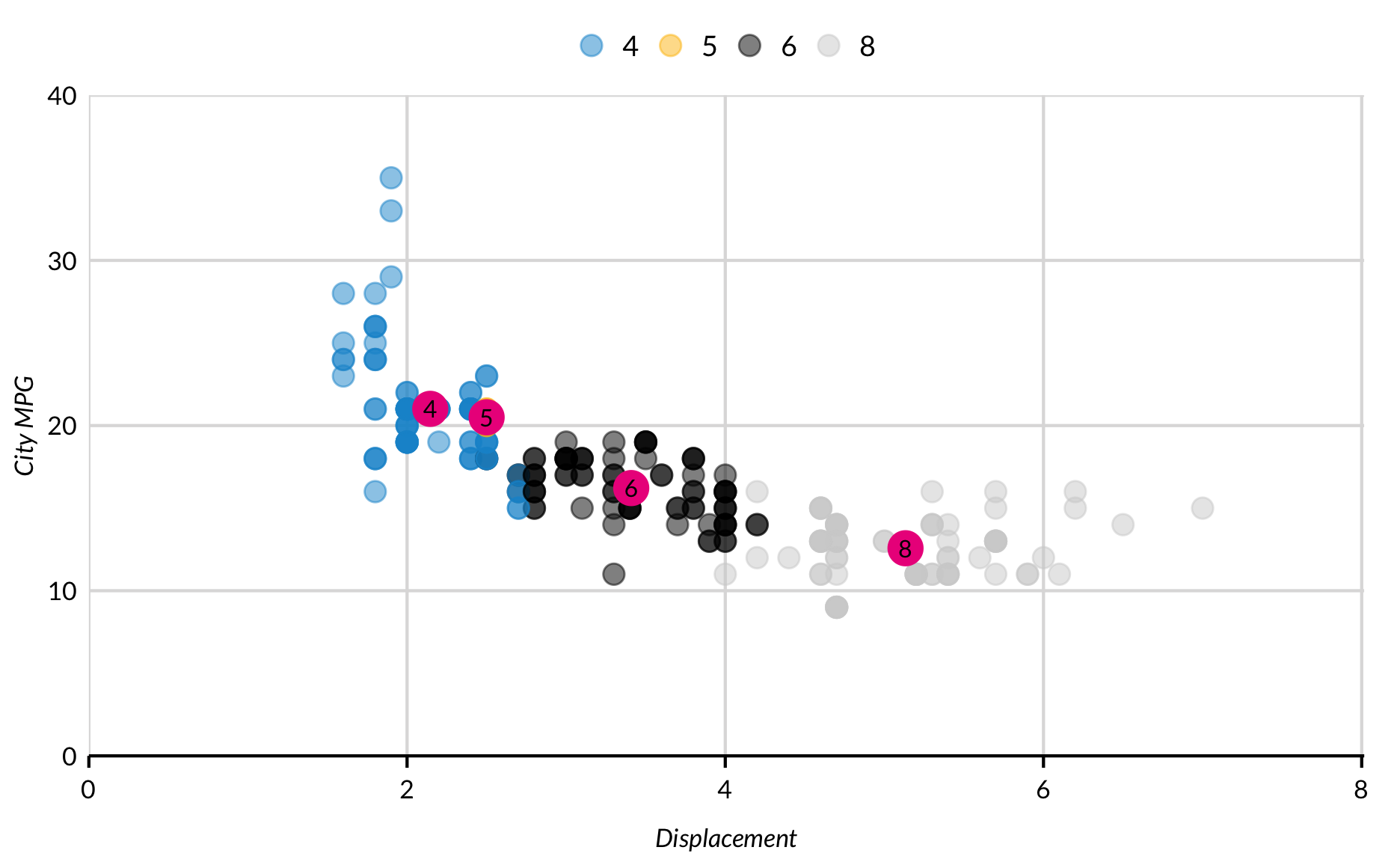
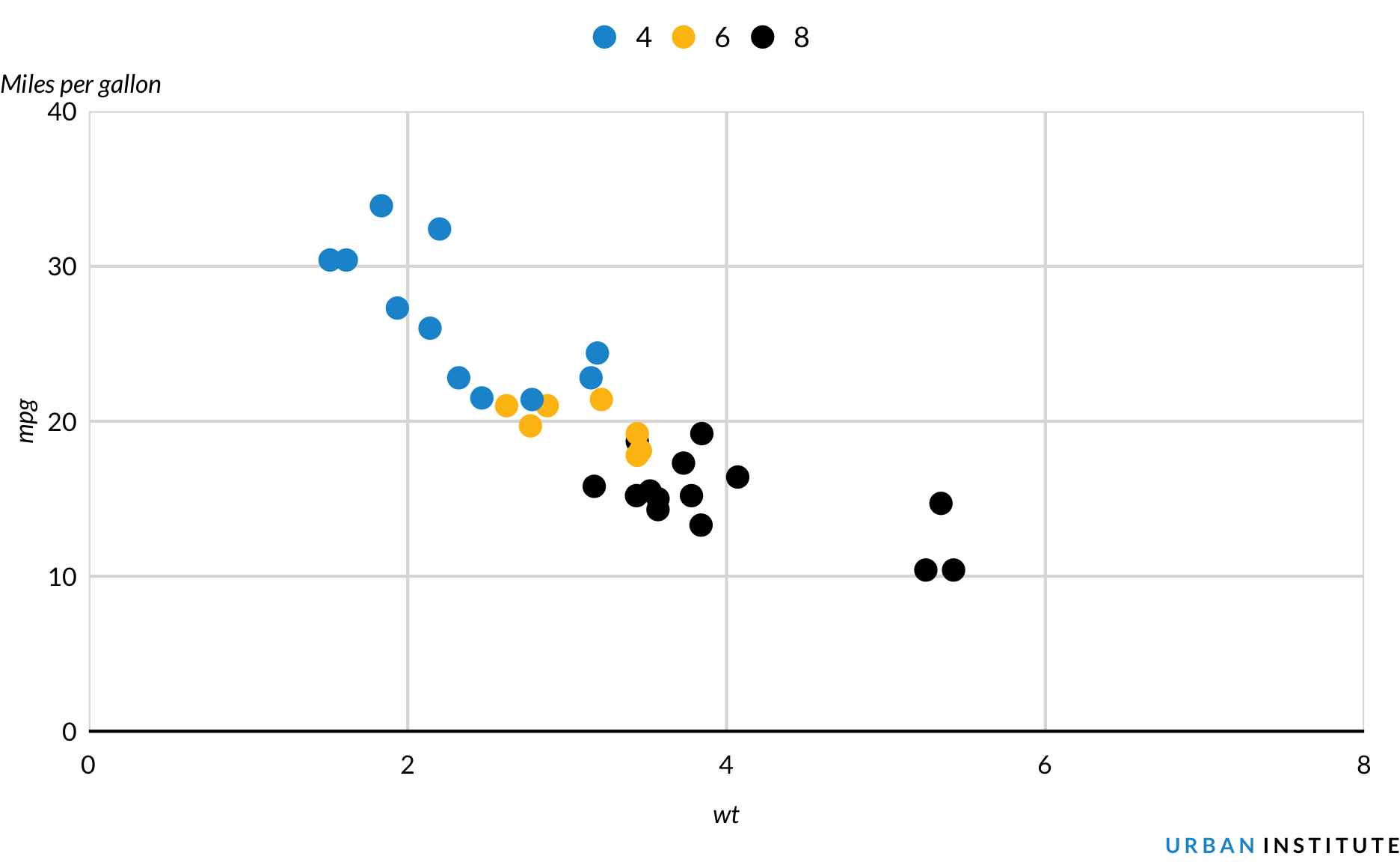
A third aesthetic can be added to scatter plots. Here, color signifies the number of cylinders in each car. Before ggplot() is called, Cylinders is created using library(dplyr) and the piping operator %>%.
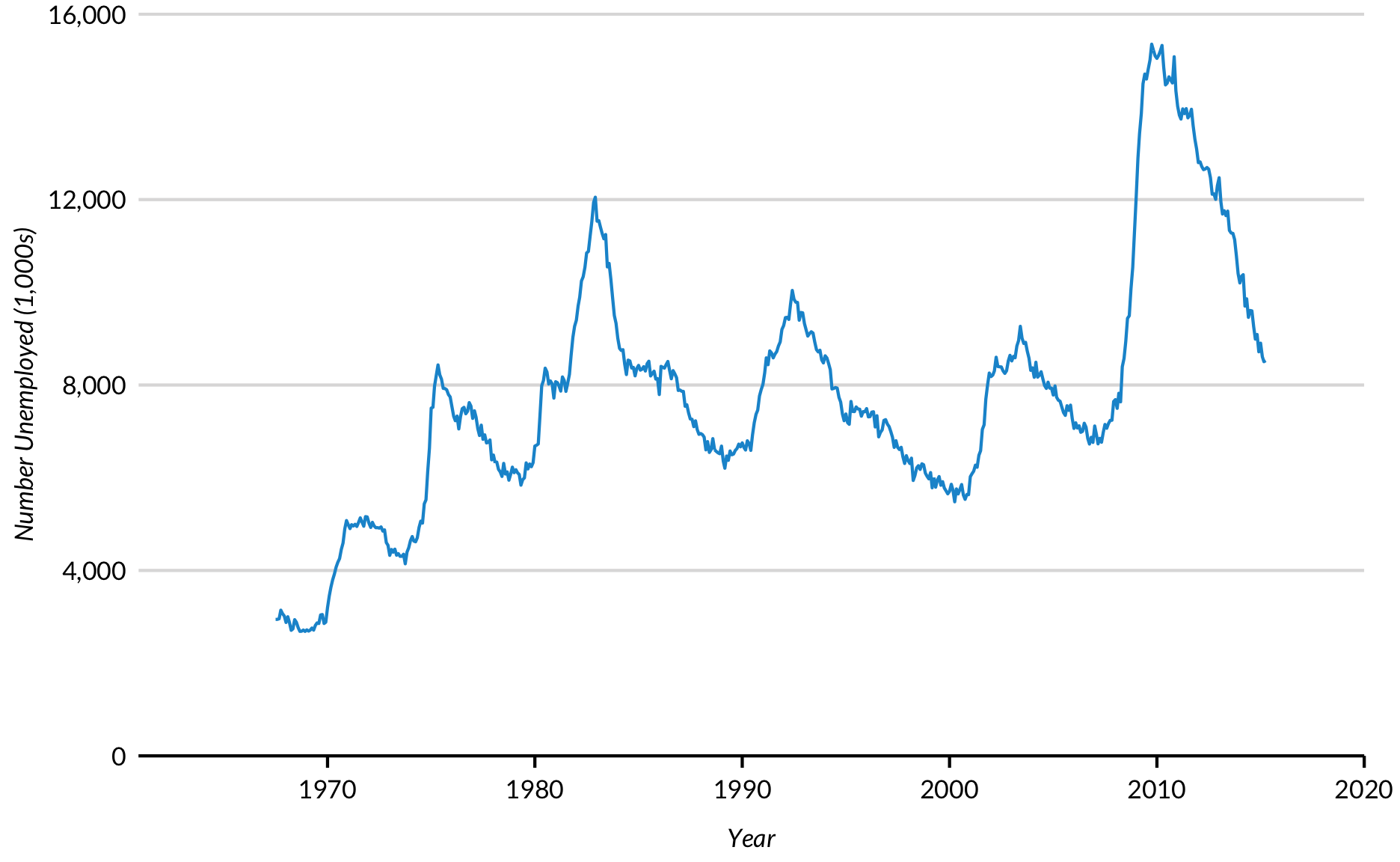
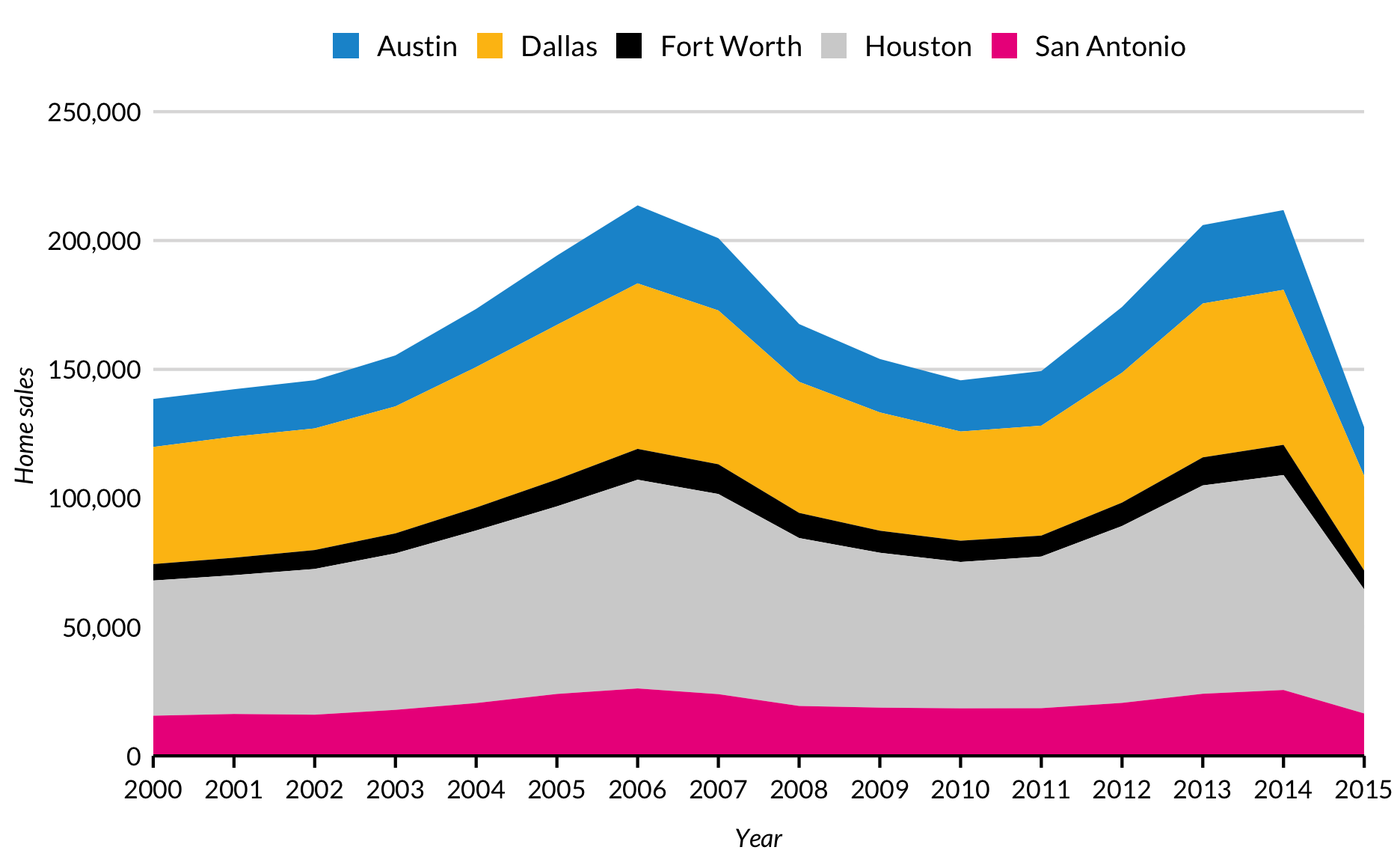
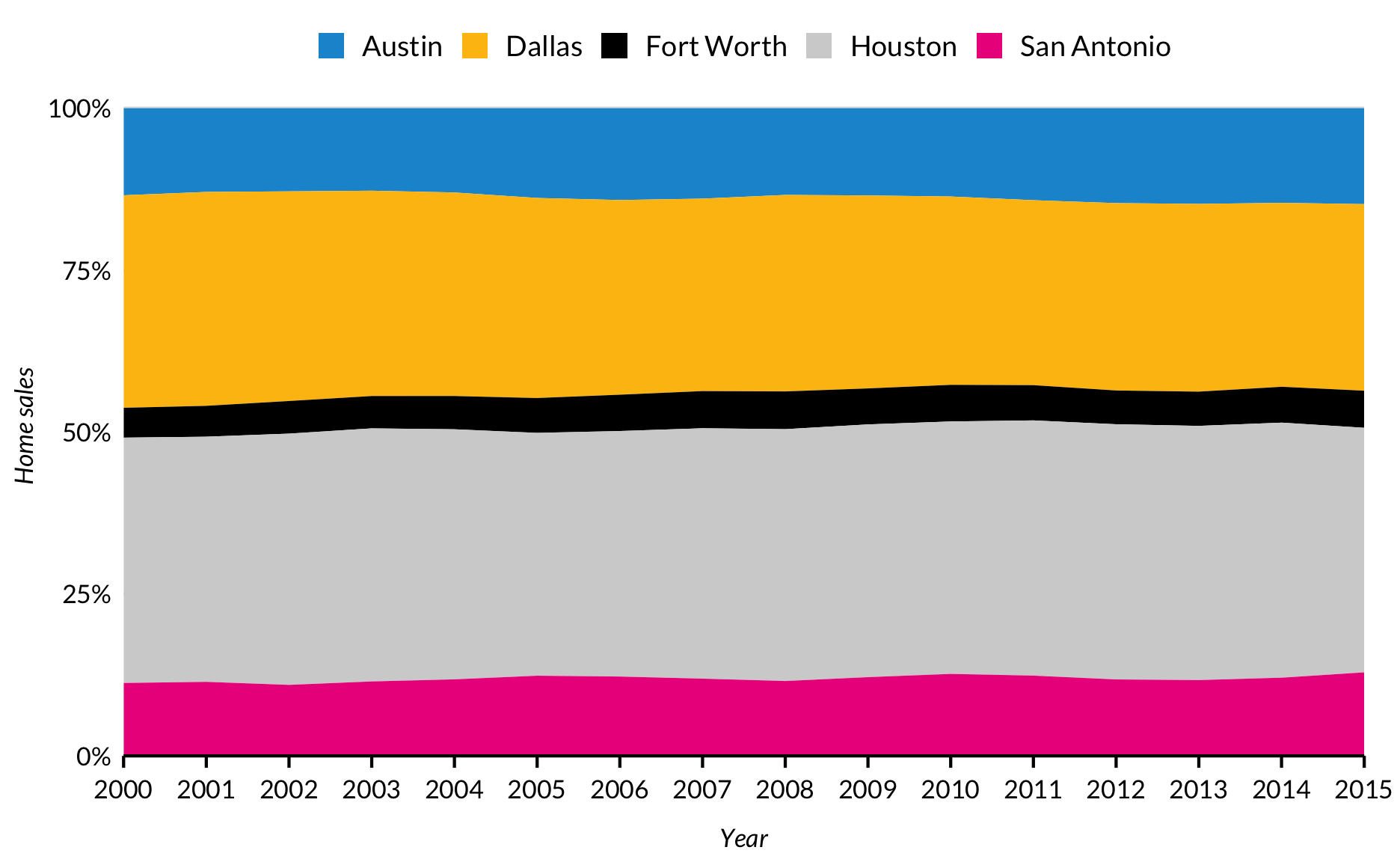
Plotting more than one variable can be useful for seeing the relationship of variables over time, but it takes a small amount of data munging.
This is because ggplot2 wants data in a “long” format instead of a “wide” format for line plots with multiple lines. gather() and spread() from the tidyr package make switching back-and-forth between “long” and “wide” painless. Essentially, variable titles go into “key” and variable values go into “value”. Then ggplot2, turns the different levels of the key variable (population, unemployment) into colors.
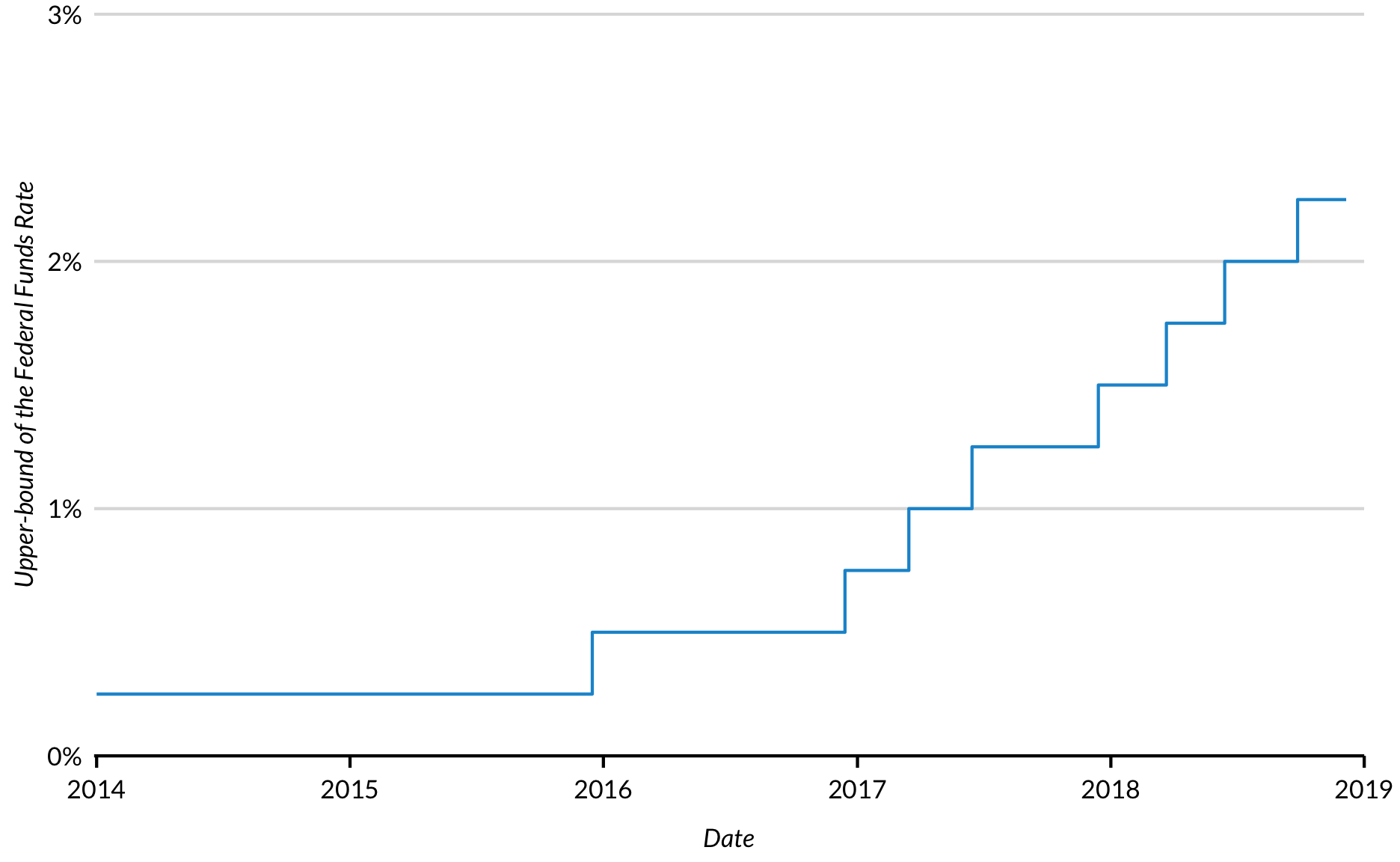
geom_line() connects coordinates with the shortest possible straight line. Sometimes step plots are necessary because y values don’t change between coordinates. For example, the upper-bound of the Federal Funds Rate is set at regular intervals and remains constant until it is changed.
# downloaded from FRED on 2018-12-06# https://fred.stlouisfed.org/series/DFEDTARUfed_fund_rate <-read_csv("date, fed_funds_rate 2014-01-01,0.0025 2015-12-16,0.0050 2016-12-14,0.0075 2017-03-16,0.0100 2017-06-15,0.0125 2017-12-14,0.0150 2018-03-22,0.0175 2018-06-14,0.0200 2018-09-27,0.0225 2018-12-06,0.0225")fed_fund_rate %>%ggplot(mapping =aes(x = date, y = fed_funds_rate)) +geom_step() +scale_x_date(expand =expansion(mult =c(0.002, 0)), breaks ="1 year",limits =c(as.Date("2014-01-01"), as.Date("2019-01-01")),date_labels ="%Y") +scale_y_continuous(expand =expansion(mult =c(0, 0.002)), breaks =c(0, 0.01, 0.02, 0.03),limits =c(0, 0.03),labels = scales::percent) +labs(x ="Date",y ="Upper-bound of the Federal Funds Rate")
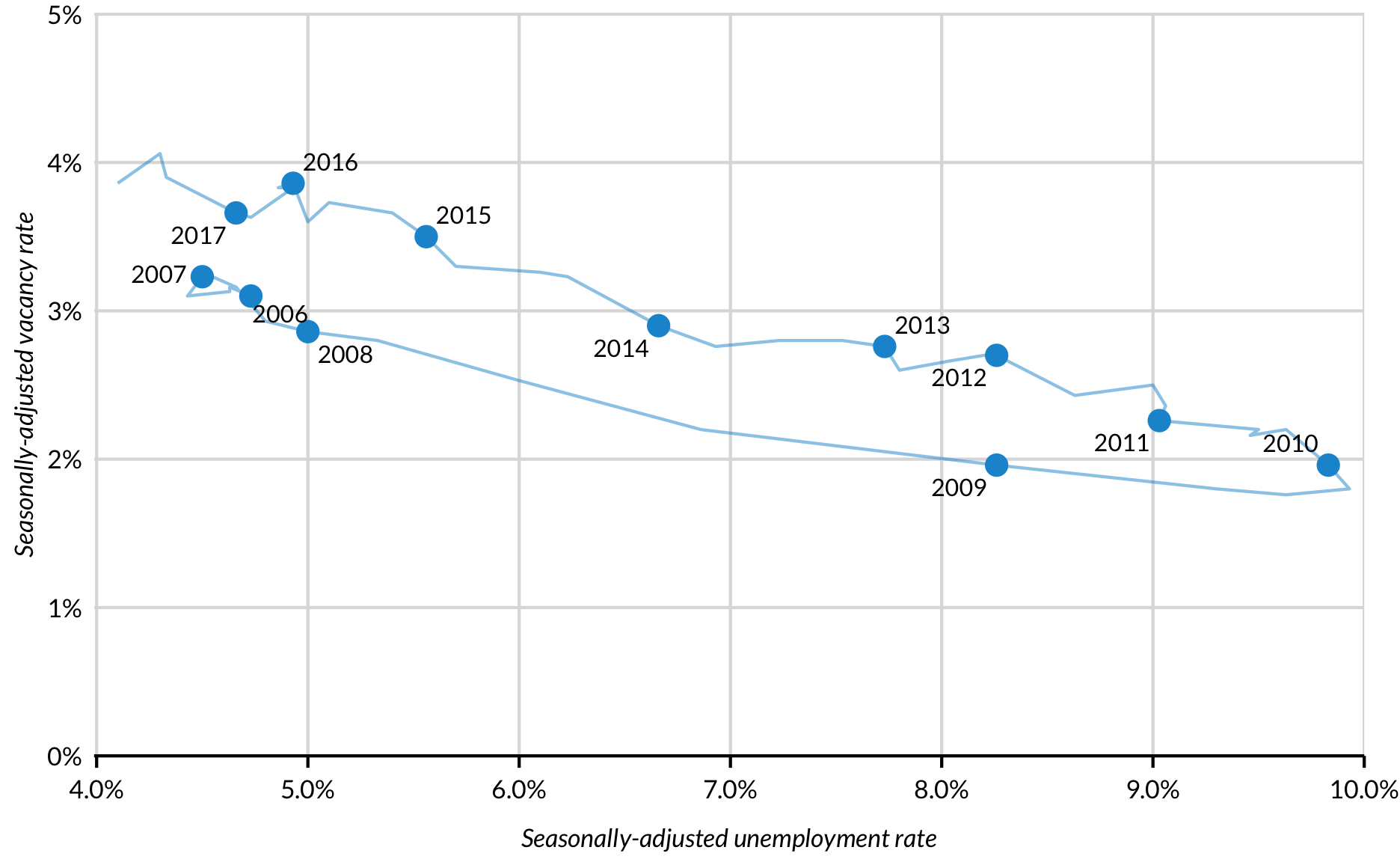
Path plot
The Beveridge curve is a macroeconomic plot that displays a relationship between the unemployment rate and the vacancy rate. Movements along the curve indicate changes in the business cyle and horizontal shifts of the curve suggest structural changes in the labor market.
Lines in Beveridge curves do not monotonically move from left to right. Therefore, it is necessary to use geom_path().
There are a number of ways to explore the distributions of univariate data in R. Some methods, like strip charts, show all data points. Other methods, like the box and whisker plot, show selected data points that communicate key values like the median and 25th percentile. Finally, some methods don’t show any of the underlying data but calculate density estimates. Each method has advantages and disadvantages, so it is worthwhile to understand the different forms. For more information, read 40 years of boxplots by Hadley Wickham and Lisa Stryjewski.
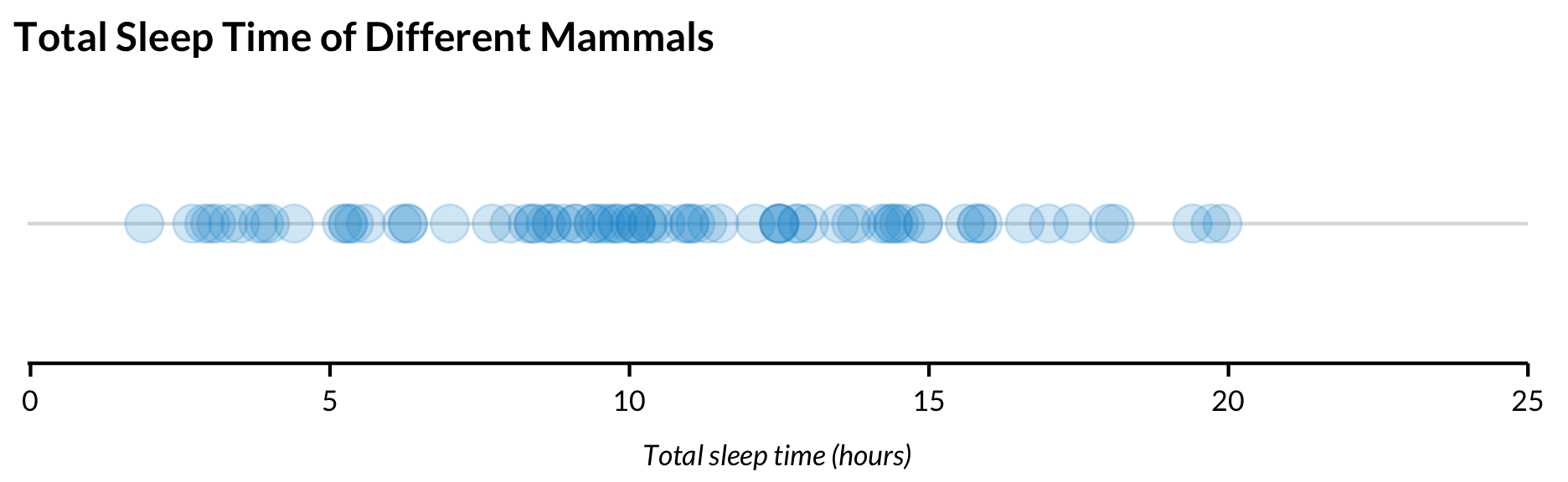
Strip Chart
Strip charts, the simplest univariate plot, show the distribution of values along one axis. Strip charts work best with variables that have plenty of variation. If not, the points tend to cluster on top of each other. Even if the variable has plenty of variation, it is often important to add transparency to the points with alpha = so overlapping values are visible.
msleep %>%ggplot(aes(x = sleep_total, y =factor(1))) +geom_point(alpha =0.2, size =5) +labs(y =NULL) +scale_x_continuous(expand =expansion(mult =c(0.002, 0)), limits =c(0, 25), breaks =0:5*5) +scale_y_discrete(labels =NULL) +labs(title ="Total Sleep Time of Different Mammals",x ="Total sleep time (hours)",y =NULL) +theme(axis.ticks.y =element_blank())
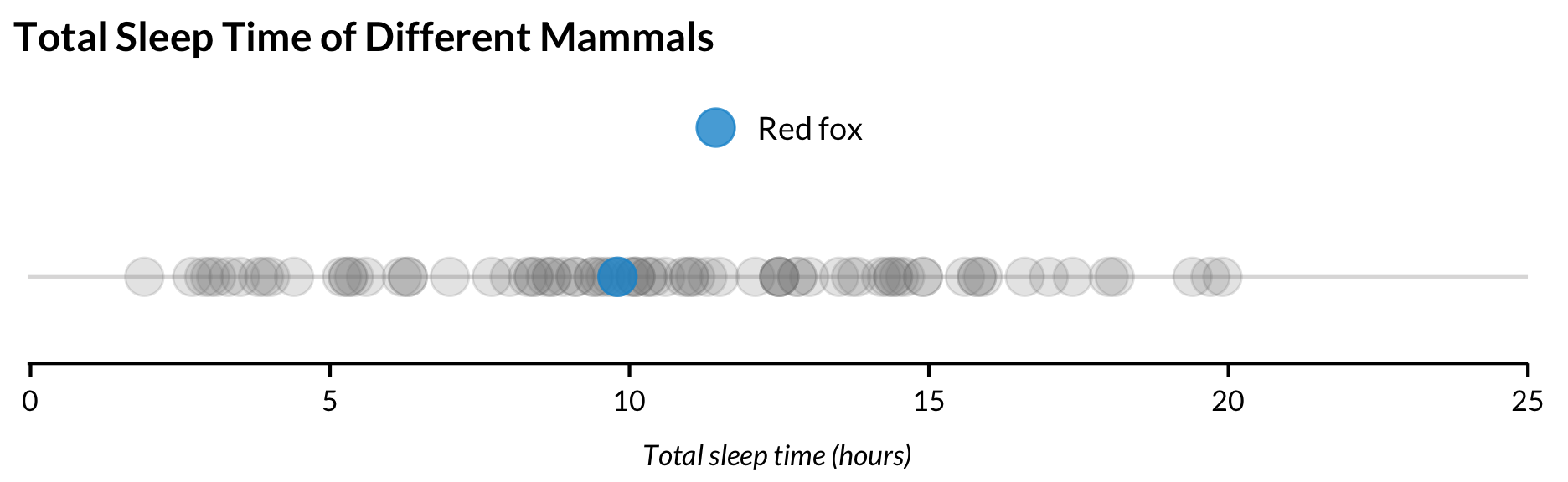
Strip Chart with Highlighting
Because strip charts show all values, they are useful for showing where selected points lie in the distribution of a variable. The clearest way to do this is by adding geom_point() twice with filter() in the data argument. This way, the highlighted values show up on top of unhighlighted values.
ggplot() +geom_point(data =filter(msleep, name !="Red fox"), aes(x = sleep_total, y =factor(1)),alpha =0.2, size =5,color ="grey50") +geom_point(data =filter(msleep, name =="Red fox"),aes(x = sleep_total, y =factor(1), color = name),alpha =0.8,size =5) +scale_x_continuous(expand =expansion(mult =c(0.002, 0)), limits =c(0, 25), breaks =0:5*5) +scale_y_discrete(labels =NULL) +labs(title ="Total Sleep Time of Different Mammals",x ="Total sleep time (hours)",y =NULL, legend) +guides(color =guide_legend(title =NULL)) +theme(axis.ticks.y =element_blank())
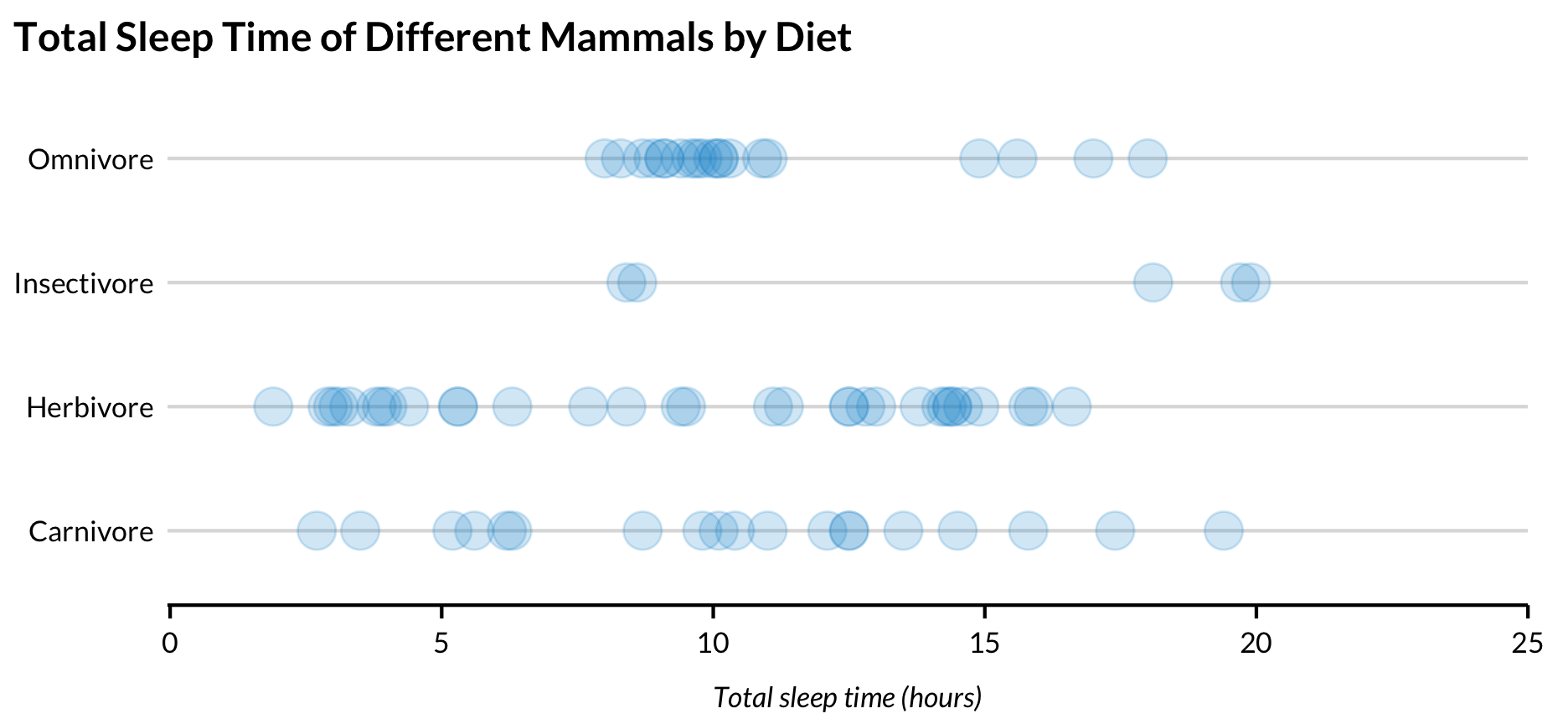
Subsetted Strip Chart
Add a y variable to see the distributions of the continuous variable in subsets of a categorical variable.
library(forcats)msleep %>%filter(!is.na(vore)) %>%mutate(vore =fct_recode(vore, "Insectivore"="insecti","Omnivore"="omni", "Herbivore"="herbi", "Carnivore"="carni" )) %>%ggplot(aes(x = sleep_total, y = vore)) +geom_point(alpha =0.2, size =5) +scale_x_continuous(expand =expansion(mult =c(0.002, 0)), limits =c(0, 25), breaks =0:5*5) +labs(title ="Total Sleep Time of Different Mammals by Diet",x ="Total sleep time (hours)",y =NULL) +theme(axis.ticks.y =element_blank())
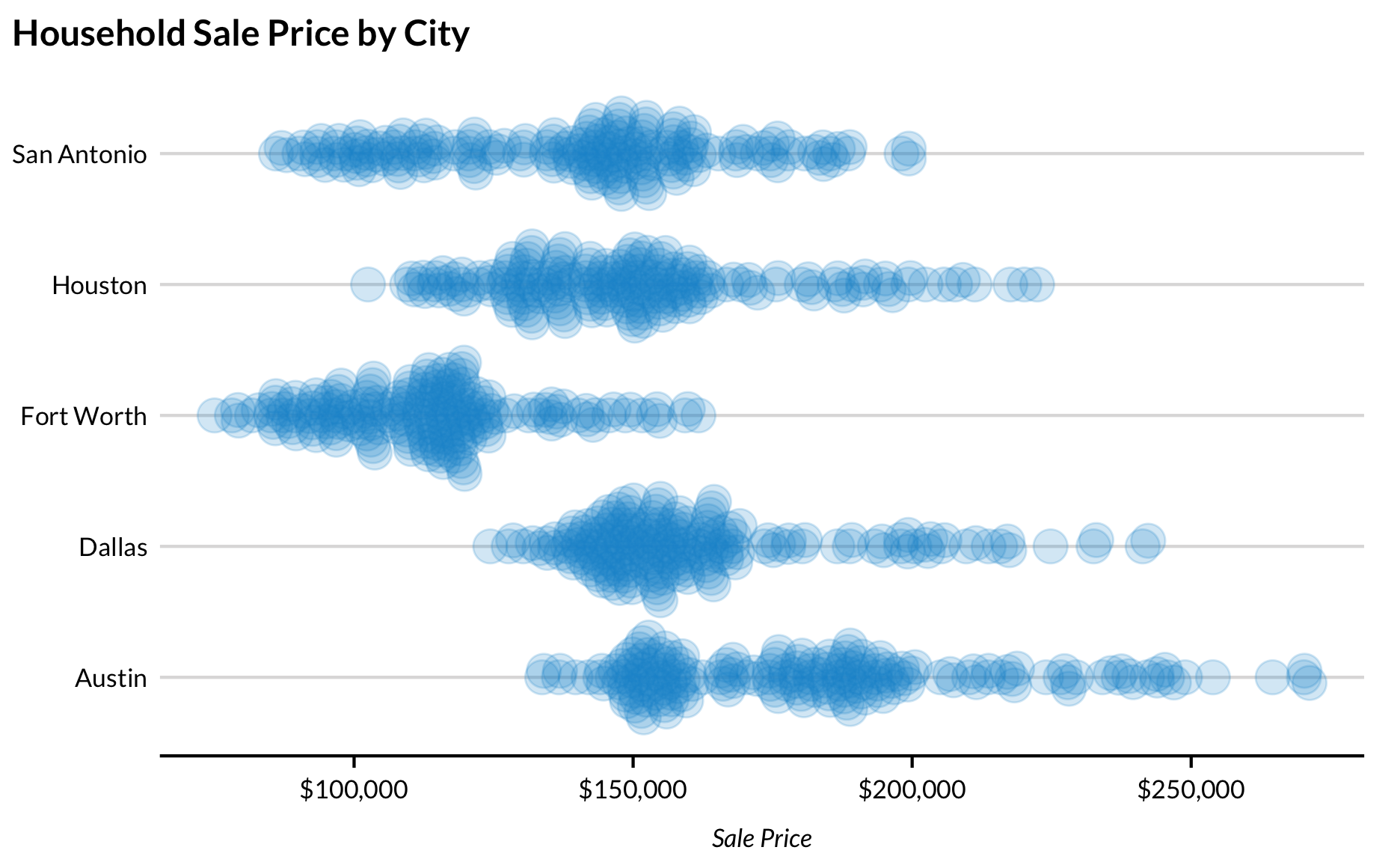
Beeswarm Plots
Beesward plots are a variation of strip charts that shows the distribution of data, but without the points overlaping.
library(ggbeeswarm)txhousing %>%filter(city %in%c("Austin","Houston","Dallas","San Antonio","Fort Worth")) %>%ggplot(aes(x = median, y = city)) +geom_beeswarm(alpha =0.2, size =5) +scale_x_continuous(labels = scales::dollar) +labs(title ="Household Sale Price by City",x ="Sale Price",y =NULL) +theme(axis.ticks.y =element_blank())
Histograms
Histograms divide the distribution of a variable into n equal-sized bins and then count and display the number of observations in each bin. Histograms are sensitive to bin width. As ?geom_histogram notes, “You should always override [the default binwidth] value, exploring multiple widths to find the best to illustrate the stories in your data.”
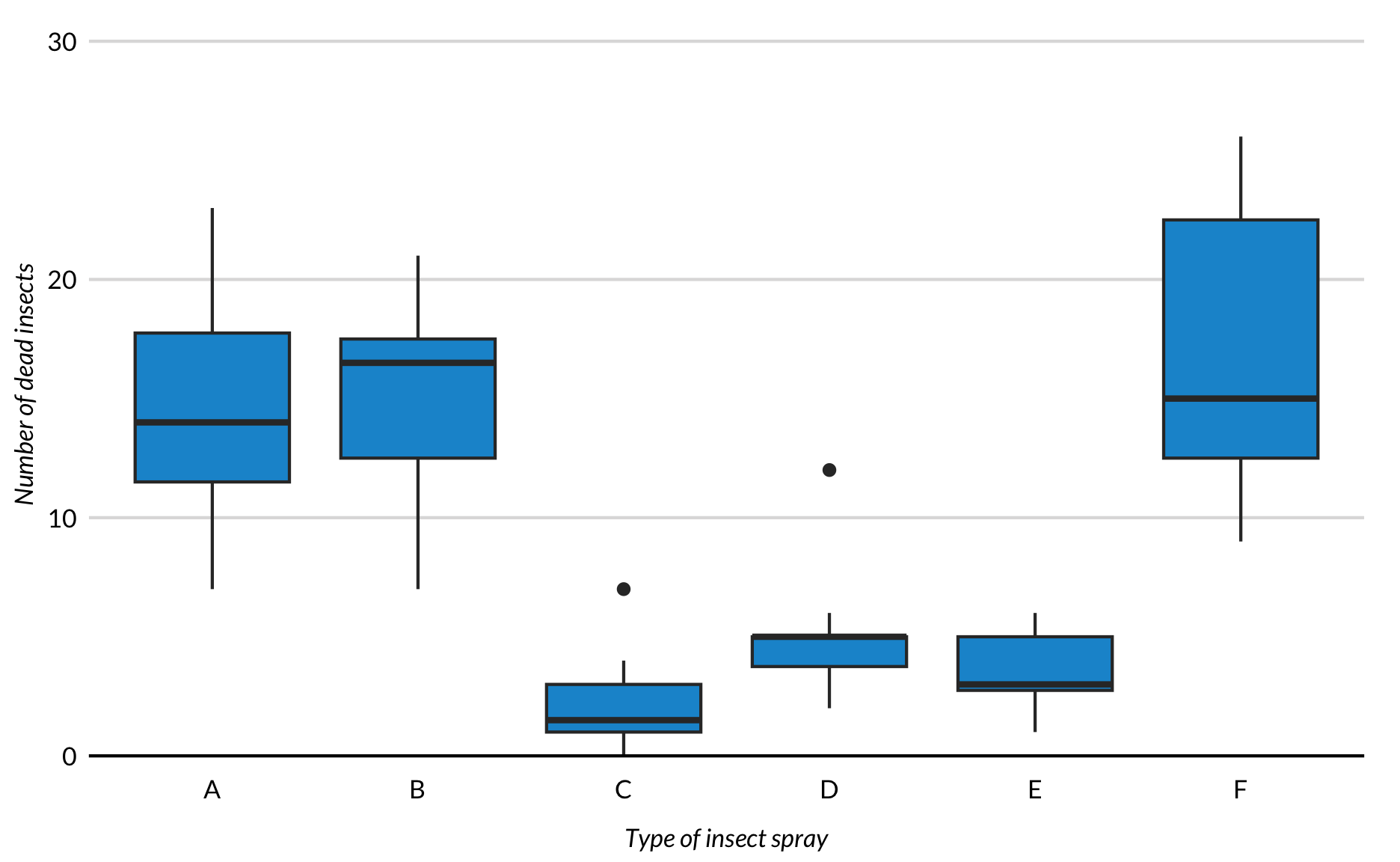
Boxplots were invented in the 1970s by John Tukey1. Instead of showing the underlying data or binned counts of the underlying data, they focus on important values like the 25th percentile, median, and 75th percentile.
InsectSprays %>%ggplot(mapping =aes(x = spray, y = count)) +geom_boxplot() +scale_y_continuous(expand =expansion(mult =c(0, 0.2))) +labs(x ="Type of insect spray",y ="Number of dead insects") +remove_ticks()
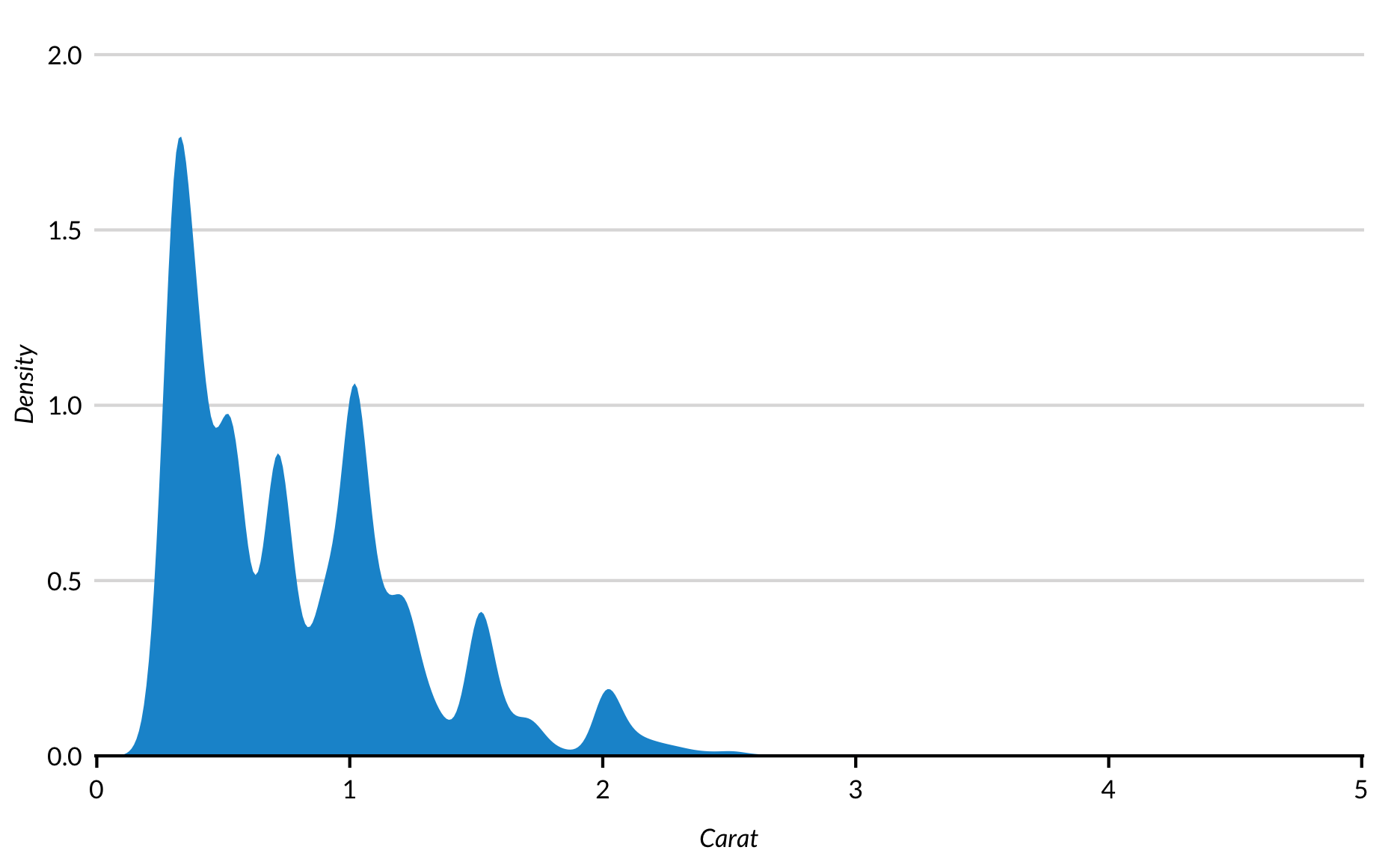
Smoothed Kernel Density Plots
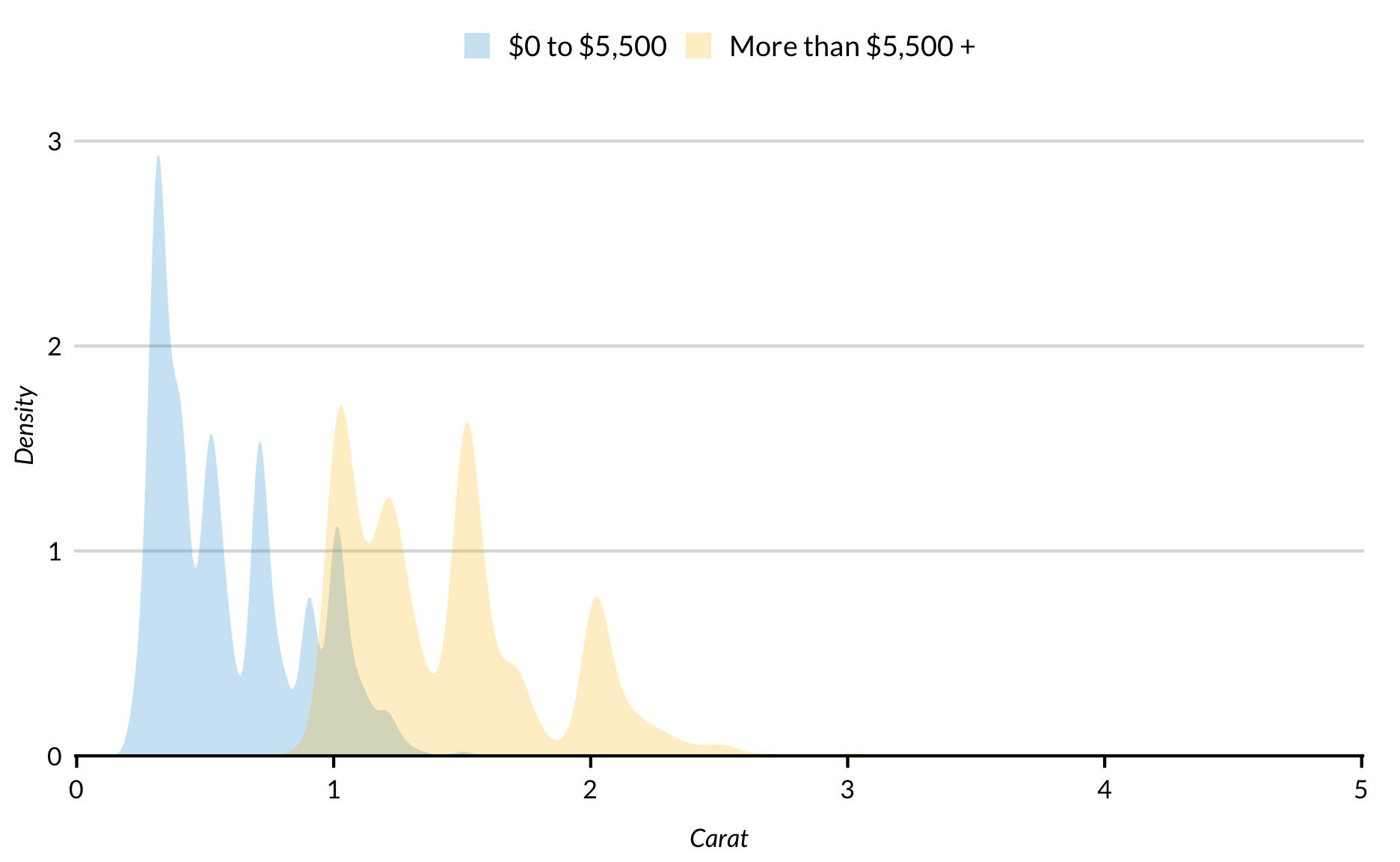
Continuous variables with smooth distributions are sometimes better represented with smoothed kernel density estimates than histograms or boxplots. geom_density() computes and plots a kernel density estimate. Notice the lumps around integers and halves in the following distribution because of rounding.
diamonds %>%mutate(cost =ifelse(price >5500, "More than $5,500 +", "$0 to $5,500")) %>%ggplot(mapping =aes(carat, fill = cost)) +geom_density(alpha =0.25, color =NA) +scale_x_continuous(expand =expansion(mult =c(0.002, 0)), limits =c(0, NA)) +scale_y_continuous(expand =expansion(mult =c(0, 0.1))) +labs(x ="Carat",y ="Density")
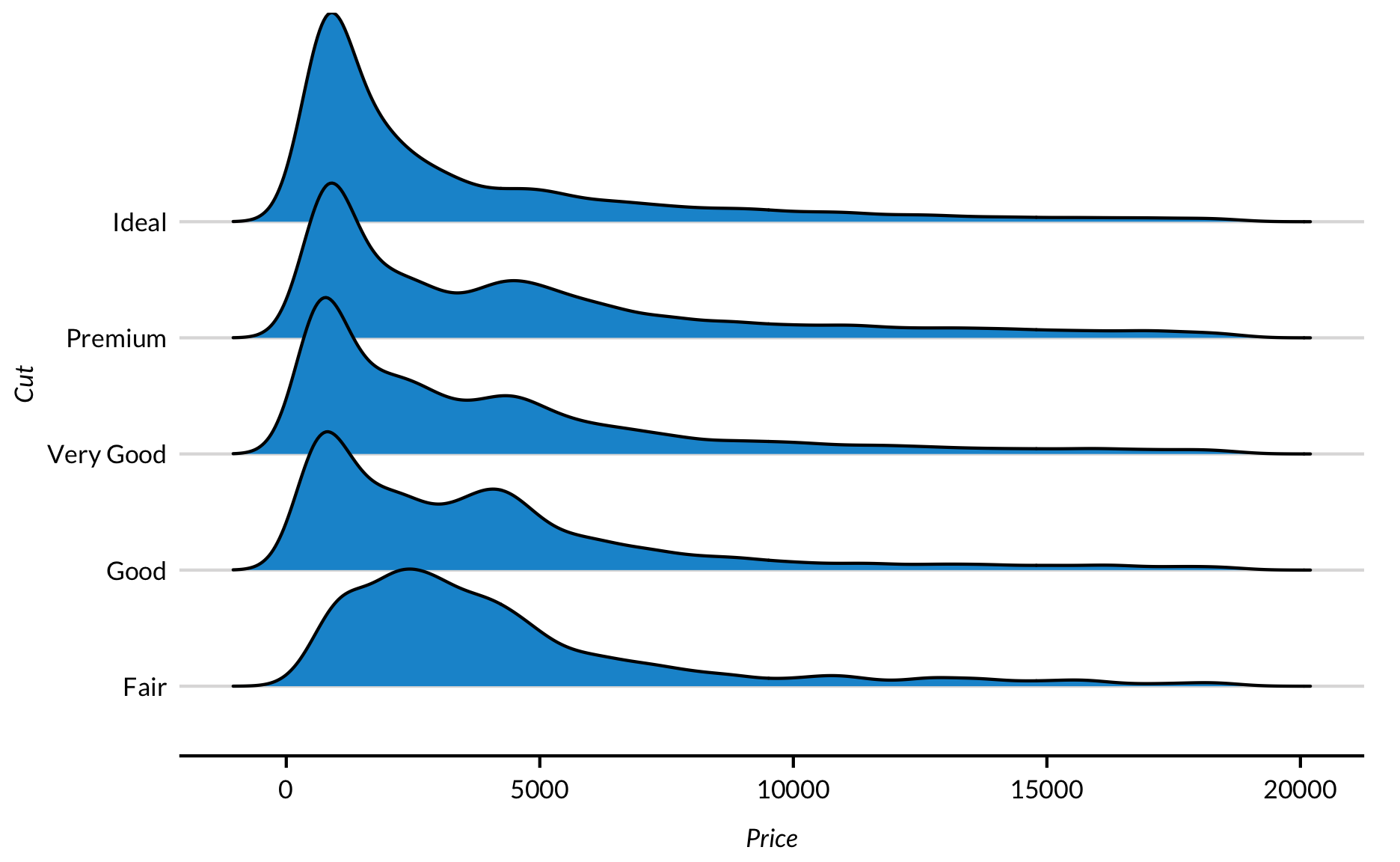
Ridgeline Plots
Ridgeline plots are partially overlapping smoothed kernel density plots faceted by a categorical variable that pack a lot of information into one elegant plot.
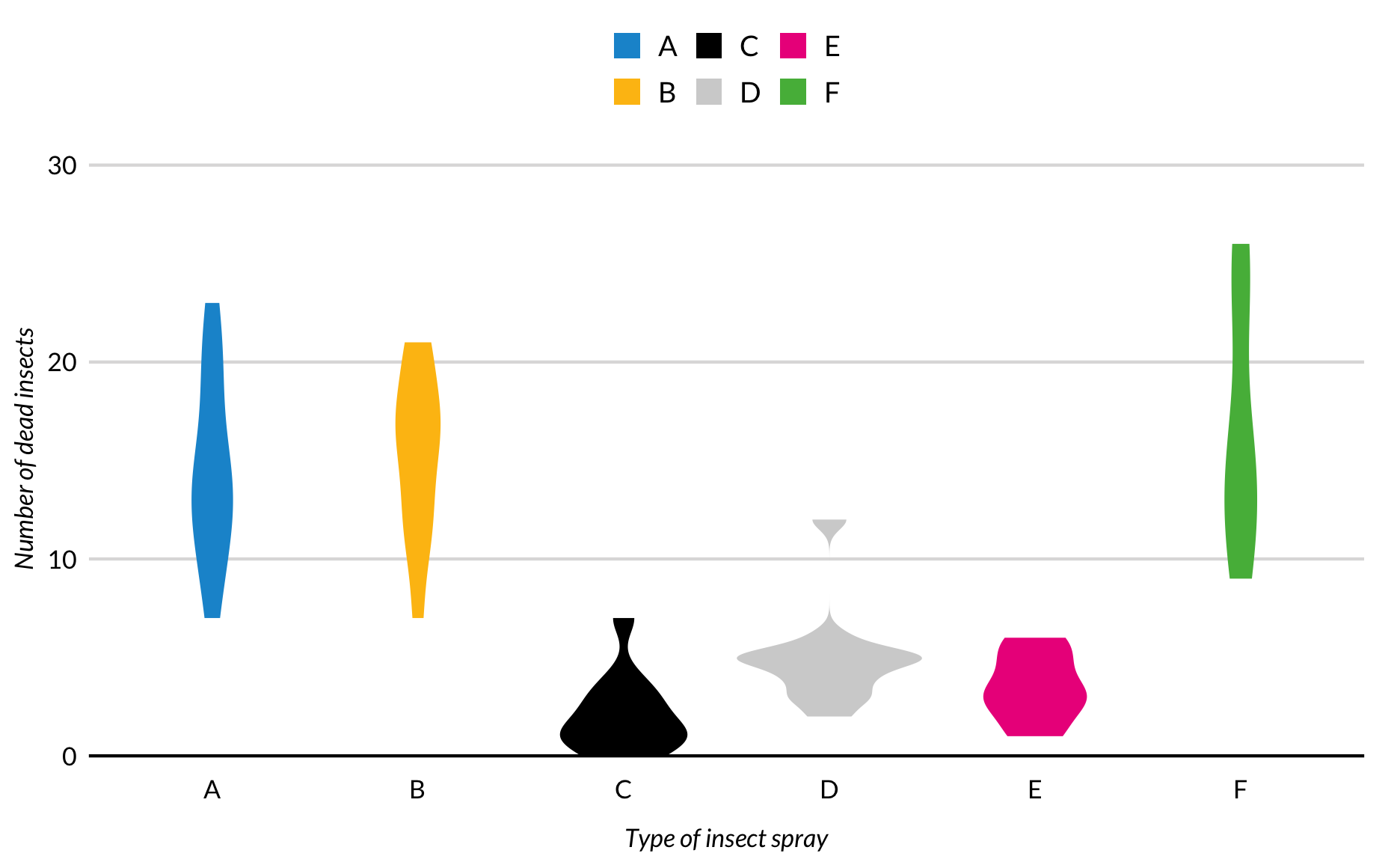
Violin plots are symmetrical displays of smooth kernel density plots.
InsectSprays %>%ggplot(mapping =aes(x = spray, y = count, fill = spray)) +geom_violin(color =NA) +scale_y_continuous(expand =expansion(mult =c(0, 0.2))) +labs(x ="Type of insect spray",y ="Number of dead insects") +remove_ticks()
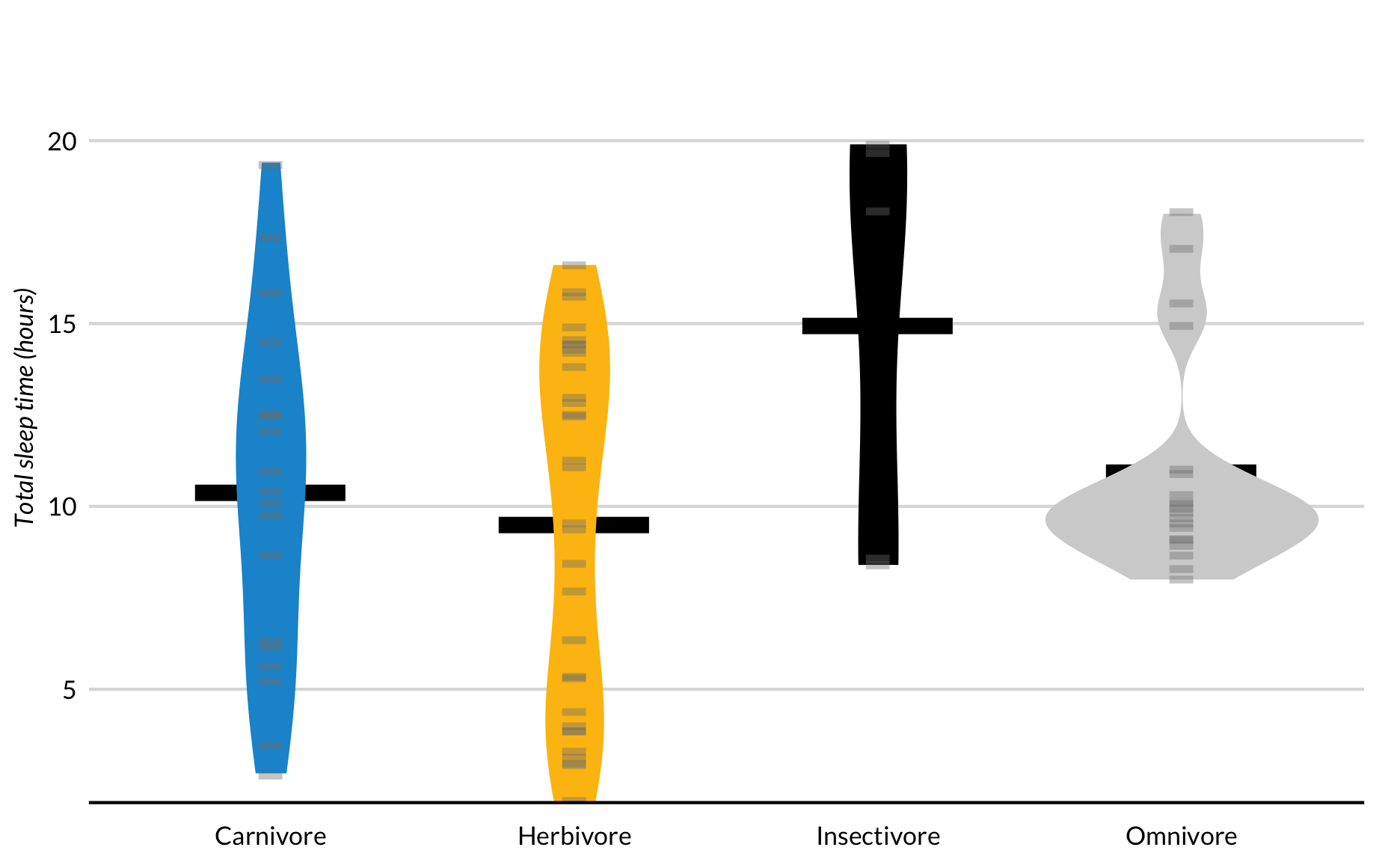
Bean Plot
Individual outliers and important summary values are not visible in violin plots or smoothed kernel density plots. Bean plots, created by Peter Kampstra in 2008, are violin plots with data shown as small lines in a one-dimensional sstrip plot and larger lines for the mean.
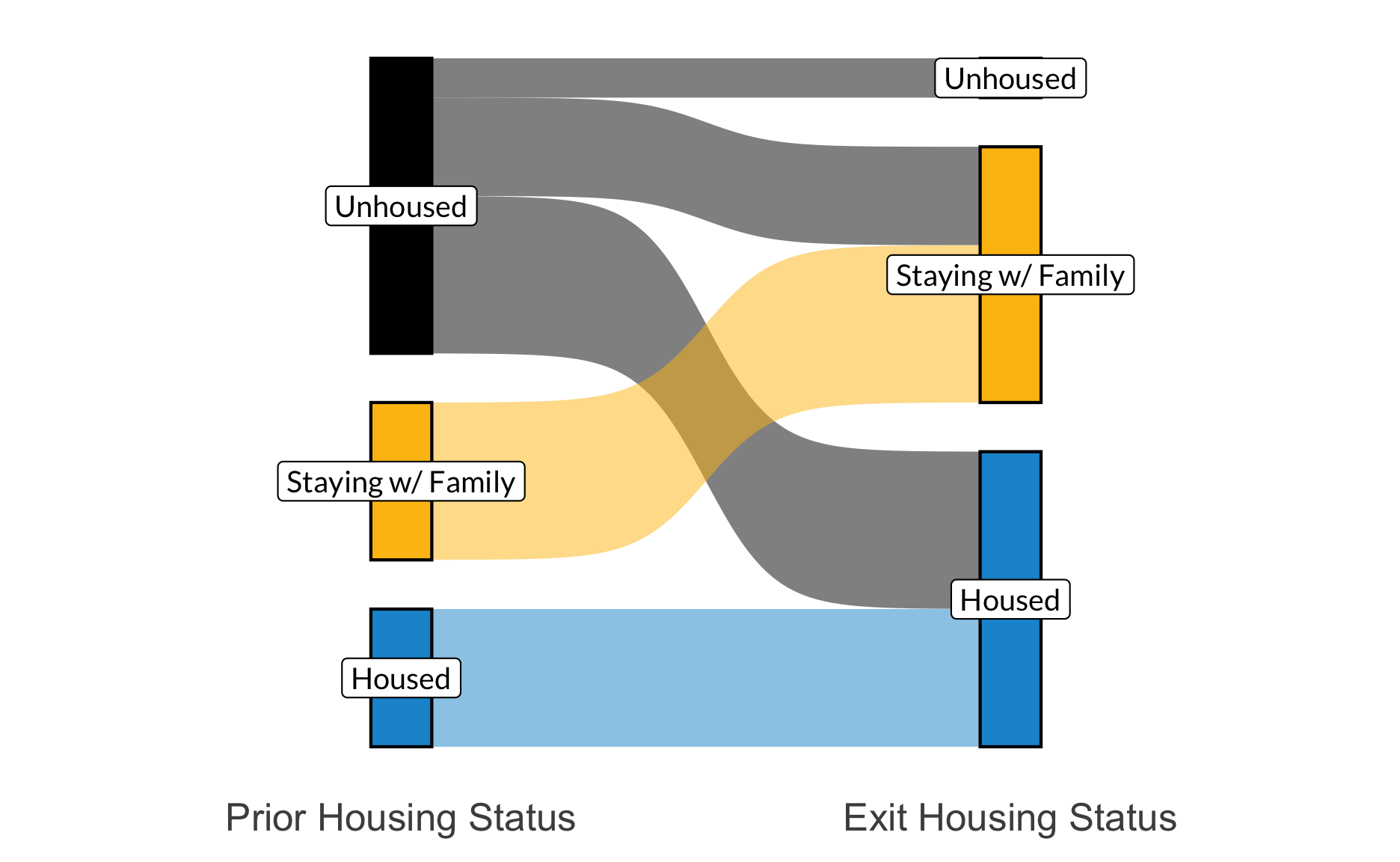
Sankey plots visualize flows from one set of variables to another. This can be useful for showing outcomes from the start of a program to the end. You’ll need to install the ggsankey package to create Sankey plots in R. In this example I make a dummy data set of housing status prior to program start and at exit to show the flow of people between outcomes. A key step is to transform your data set using the make_long function from the package. This creates a data frame that specifies each of the initial nodes and how they flow into the next stage.
# load ggsankey packageremotes::install_github("davidsjoberg/ggsankey")library(ggsankey)# create a dummy dataset of housing statusdf <-data_frame(entry_status =c(rep("Housed", 7), rep("Unhoused", 15), rep("Staying w/ Family", 8)), exit_status =c(rep("Housed", 15), rep("Unhoused", 2), rep("Staying w/ Family", 13))) %>%# transform the data frame into the proper format for the sankey plotmake_long(entry_status, exit_status) %>%# recode the labels to be cleaner in the plot mutate(x =recode(x, entry_status ="Prior Housing Status", exit_status ="Exit Housing Status"),next_x =recode(next_x, entry_status ="Prior Housing Status", exit_status ="Exit Housing Status"))# create sankey plotggplot(df, aes(x = x, next_x = next_x, node = node, next_node = next_node,fill =factor(node), label = node)) +geom_sankey(flow.alpha =0.5, node.color =1, show.legend =FALSE) +# add labels to plot and stylegeom_sankey_label(size =3.5, color =1, fill ="white") +theme_sankey(base_size =16)+labs(x =NULL)
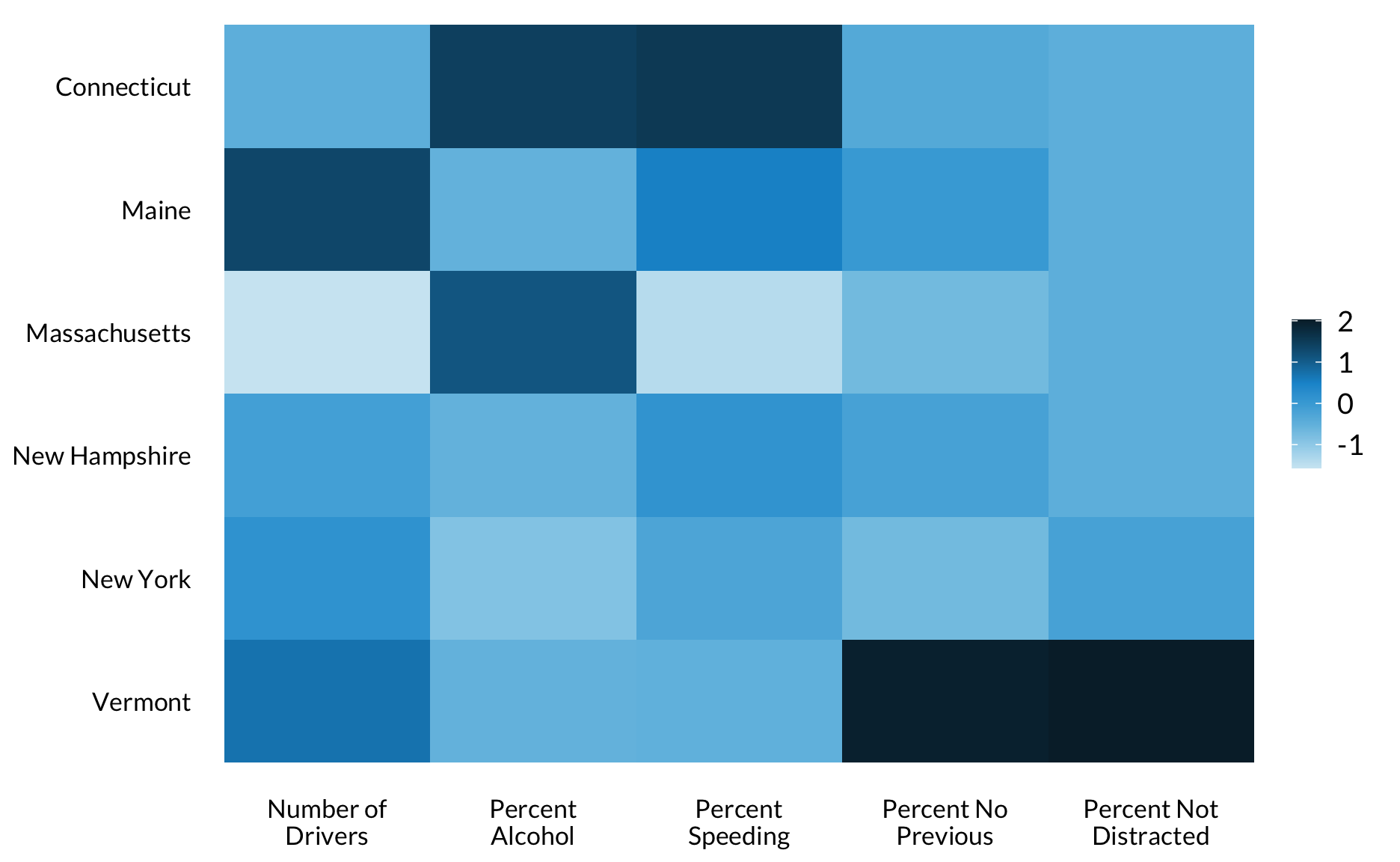
Heat Map
library(fivethirtyeight)bad_drivers %>%filter(state %in%c("Maine", "New Hampshire", "Vermont", "Massachusetts", "Connecticut", "New York")) %>%mutate(`Number of\nDrivers`=scale(num_drivers),`Percent\nSpeeding`=scale(perc_speeding),`Percent\nAlcohol`=scale(perc_alcohol),`Percent Not\nDistracted`=scale(perc_not_distracted),`Percent No\nPrevious`=scale(perc_no_previous),state =factor(state, levels =rev(state)) ) %>%select(-insurance_premiums, -losses, -(num_drivers:losses)) %>%gather(`Number of\nDrivers`:`Percent No\nPrevious`, key ="variable", value ="SD's from Mean") %>%ggplot(aes(variable, state)) +geom_tile(aes(fill =`SD's from Mean`)) +labs(x =NULL,y =NULL) +scale_fill_gradientn() +theme(legend.position ="right",legend.direction ="vertical",axis.line.x =element_blank(),panel.grid.major.y =element_blank()) +remove_ticks()
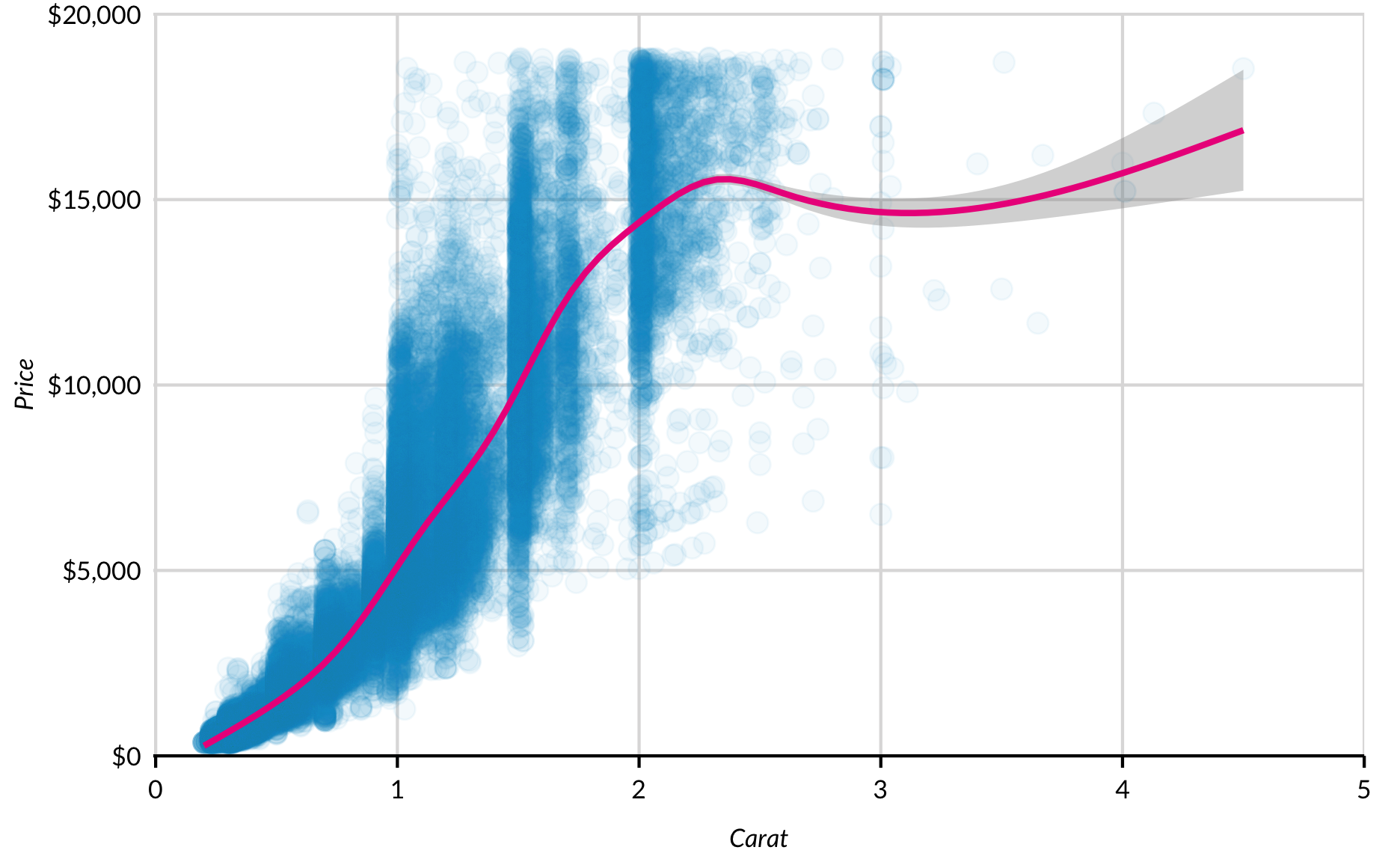
geom_smooth() fits and plots models to data with two or more dimensions.
Understanding and manipulating defaults is more important for geom_smooth() than other geoms because it contains a number of assumptions. geom_smooth() automatically uses loess for datasets with fewer than 1,000 observations and a generalized additive model with formula = y ~ s(x, bs = "cs") for datasets with greater than 1,000 observations. Both default to a 95% confidence interval with the confidence interval displayed.
Models are chosen with method = and can be set to lm(), glm(), gam(), loess(), rlm(), and more. Formulas can be specified with formula = and y ~ x syntax. Plotting the standard error is toggled with se = TRUE and se = FALSE, and level is specificed with level =. As always, more information can be seen in RStudio with ?geom_smooth().
geom_point() adds a scatterplot to geom_smooth(). The order of the function calls is important. The function called second will be layed on top of the function called first.
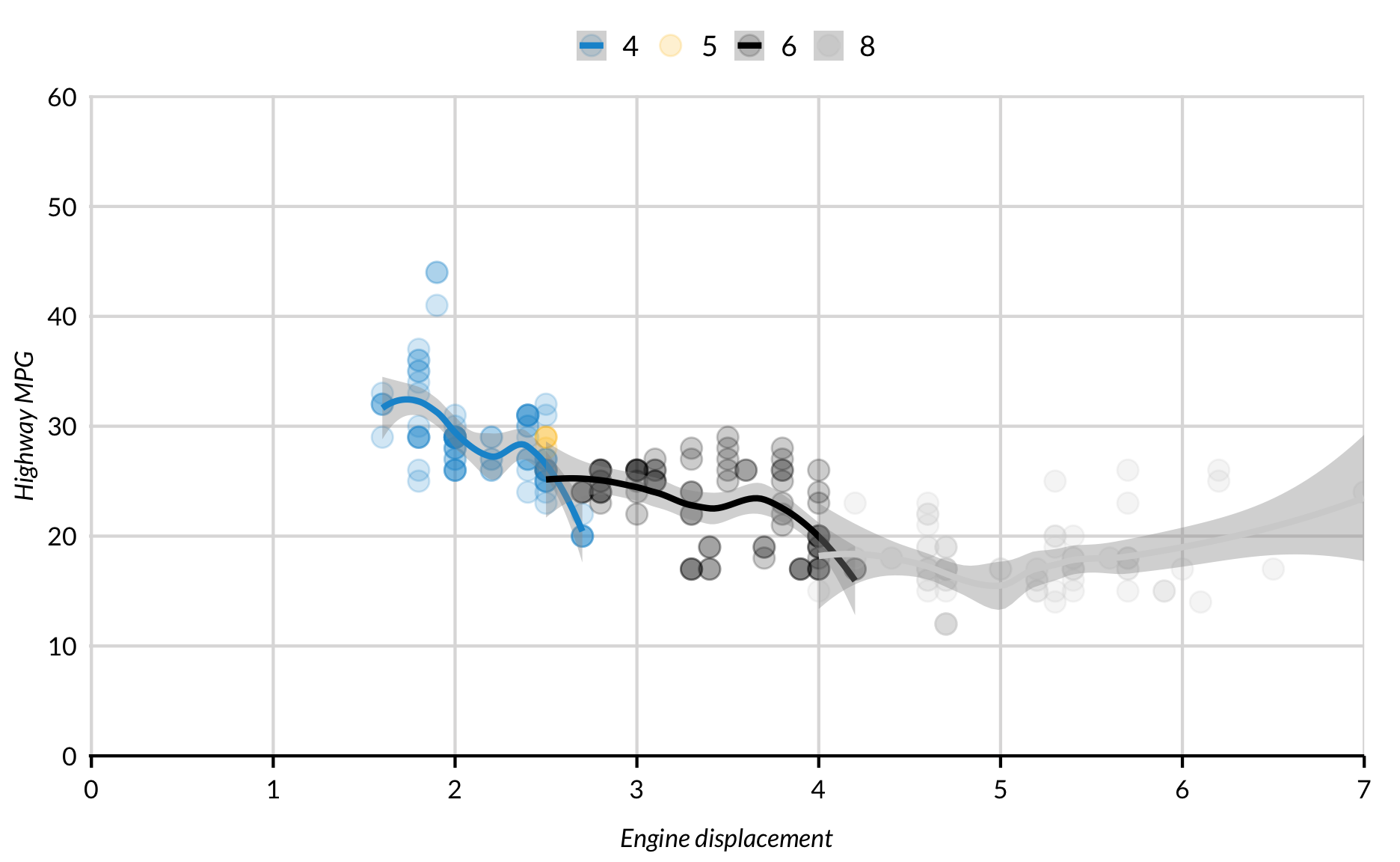
geom_smooth can be subset by categorical and factor variables. This requires subgroups to have a decent number of observations and and a fair amount of variability across the x-axis. Confidence intervals often widen at the ends so special care is needed for the chart to be meaningful and readable.
library(gghighlight) enables the intuitive highlighting of ggplot2 plots. gghighlight modifies existing ggplot2 objects, so no other code should change. All of the highlighting is handled by the function gghighlight(), which can handle all types of geoms.
Warning: R will throw an error if too many colors are highlighted because of the design of urbnthemes. Simply decrease the number of highlighted geoms to solve this issue.
There are two main ways to highlight.
Threshold
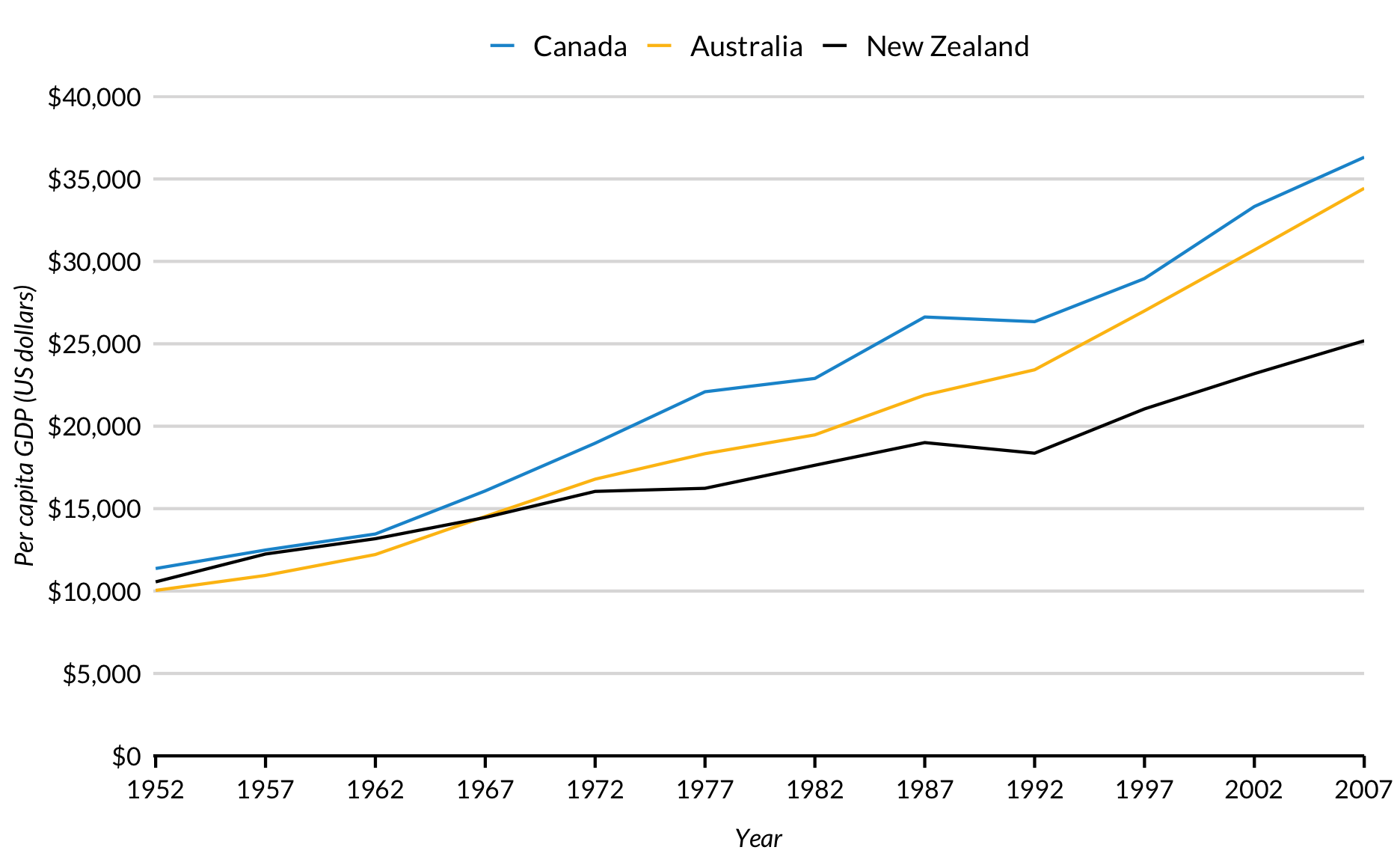
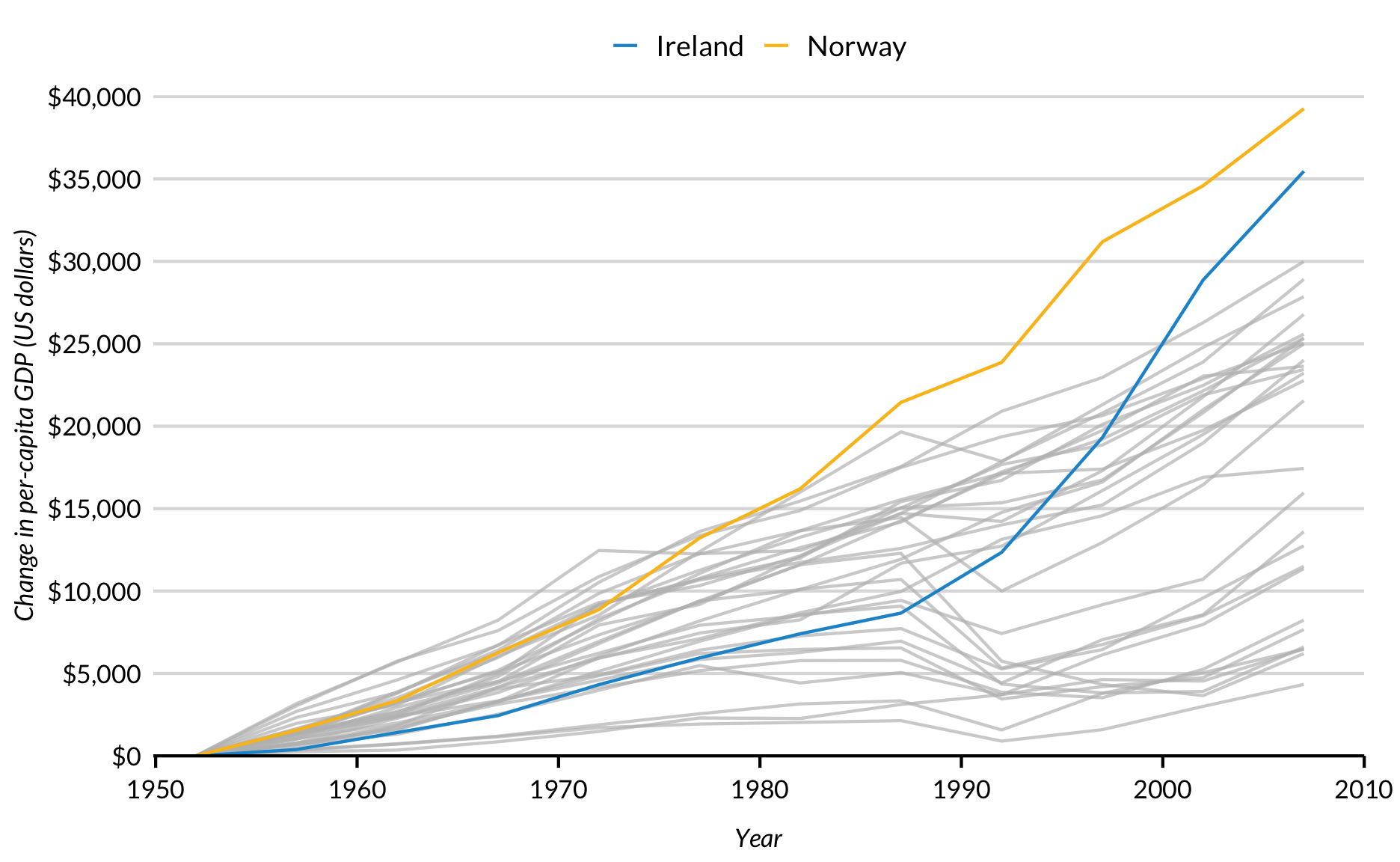
The first way to highlight is with a threshold. Add a logical test to gghighlight() to describe which lines should be highlighted. Here, lines with maximum change in per-capita Gross Domestic Product greater than $35,000 are highlighted by gghighlight(max(pcgpd_change) > 35000, use_direct_label = FALSE).
The second way to highlight is by rank. Here, the countries with the first highest values for change in per-capita Gross Domestic Product are highlighted with gghighlight(max(pcgpd_change), max_highlight = 5, use_direct_label = FALSE).
data %>%ggplot(aes(year, pcgpd_change, group = country, color = country)) +geom_line() +gghighlight(max(pcgpd_change), max_highlight =5, use_direct_label =FALSE) +scale_x_continuous(expand =expansion(mult =c(0.002, 0)),breaks =c(seq(1950, 2010, 10)),limits =c(1950, 2010)) +scale_y_continuous(expand =expansion(mult =c(0, 0.002)),breaks =0:8*5000,labels = scales::dollar,limits =c(0, 40000)) +labs(x ="Year",y ="Change in per-capita GDP (US dollars)")
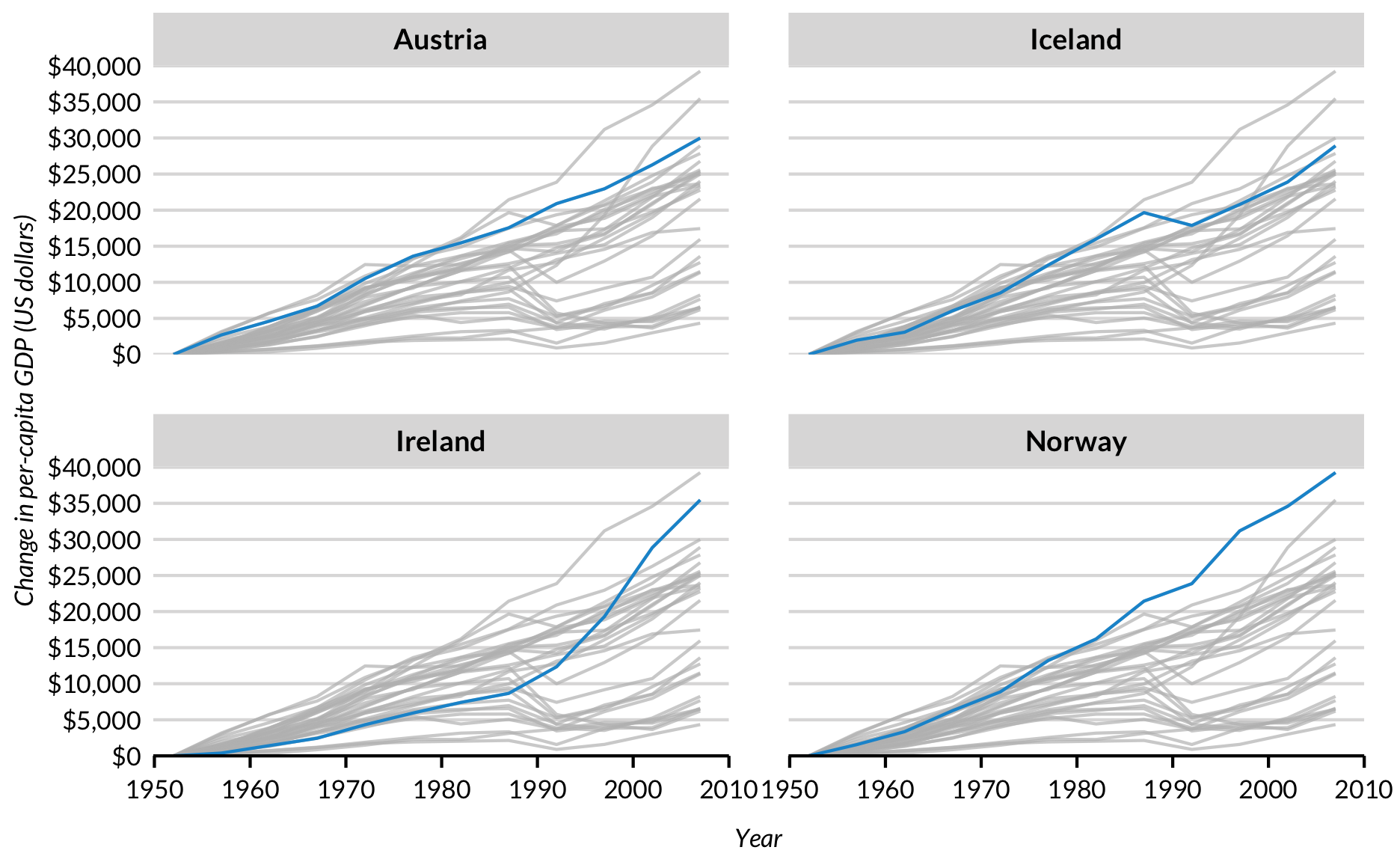
Faceting
gghighlight() works well with ggplot2’s faceting system.
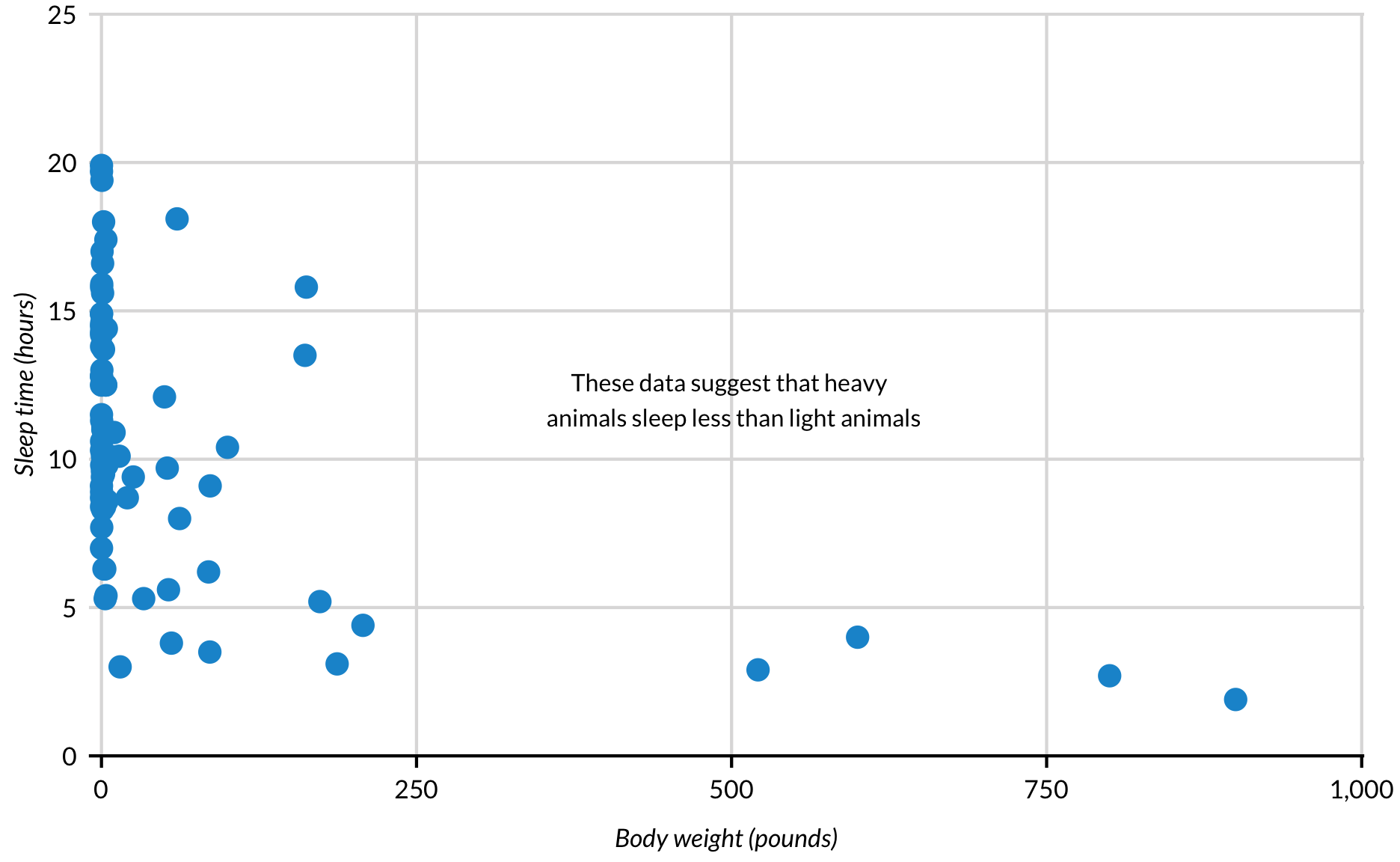
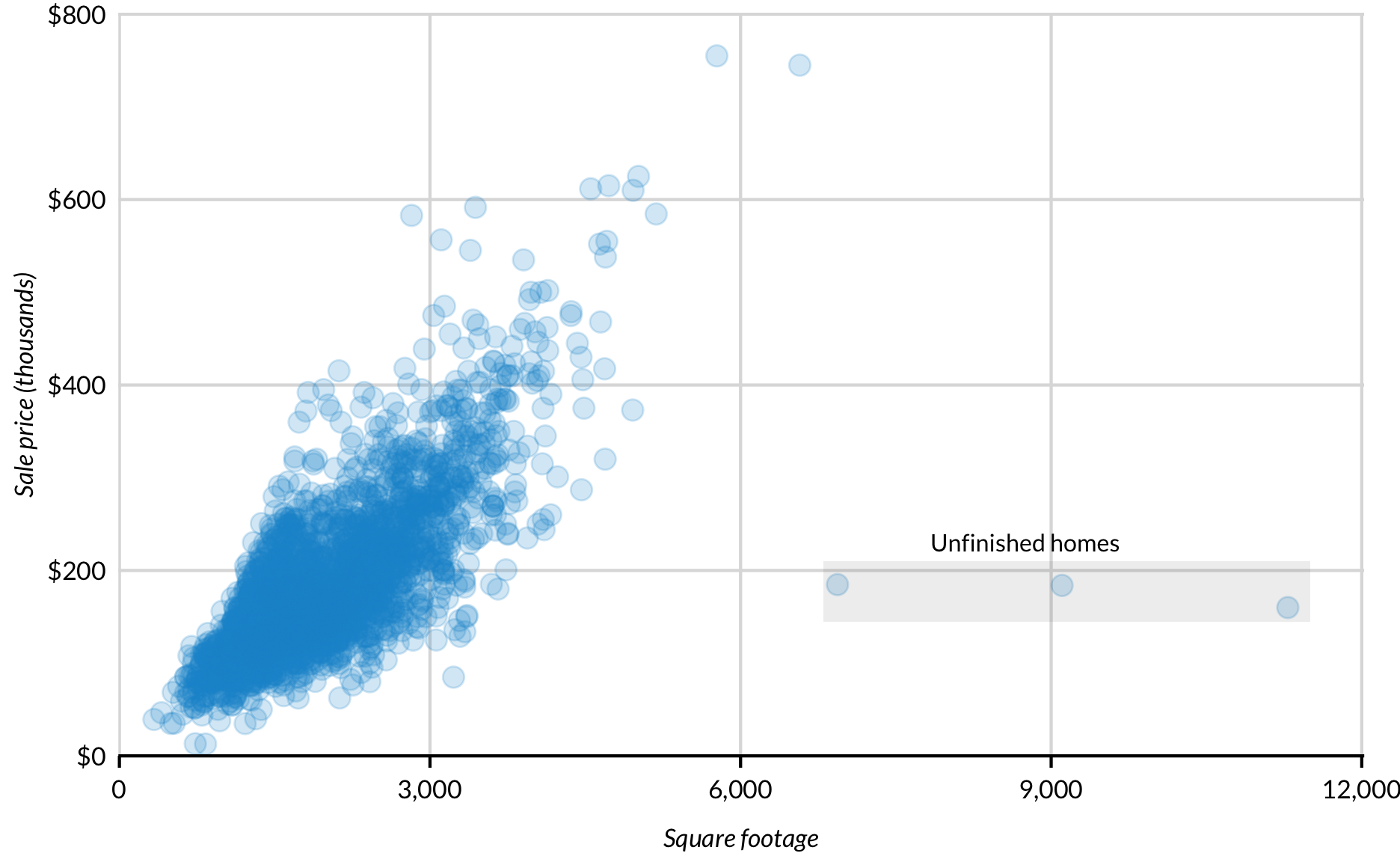
Several functions can be used to annotate, label, and highlight different parts of plots. geom_text() and geom_text_repel() both display variables from data frames. annotate(), which has several different uses, displays variables and values included in the function call.
geom_text()
geom_text() turns text variables in data sets into geometric objects. This is useful for labeling data in plots. Both functions need x values and y values to determine placement on the coordinate plane, and a text vector of labels.
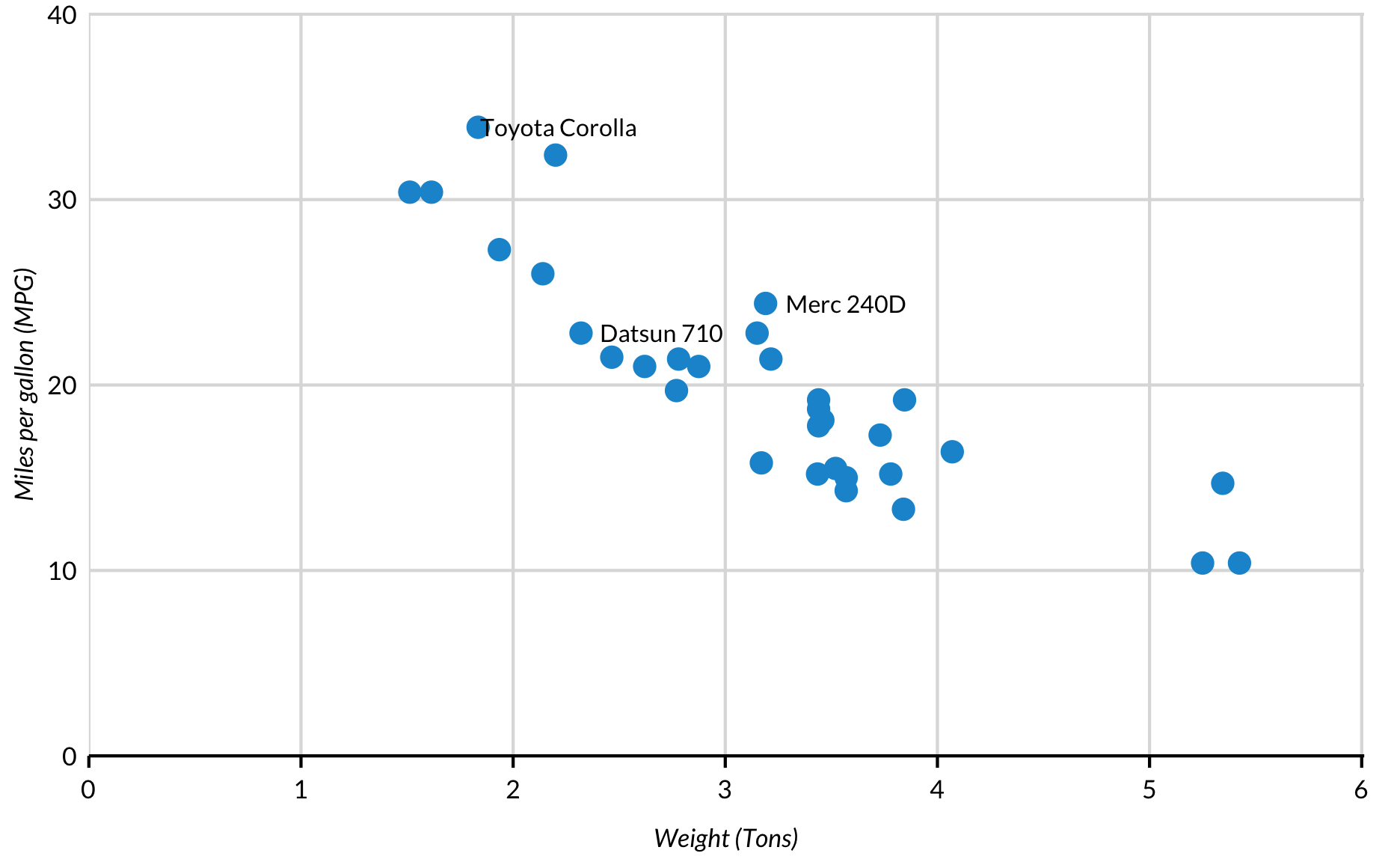
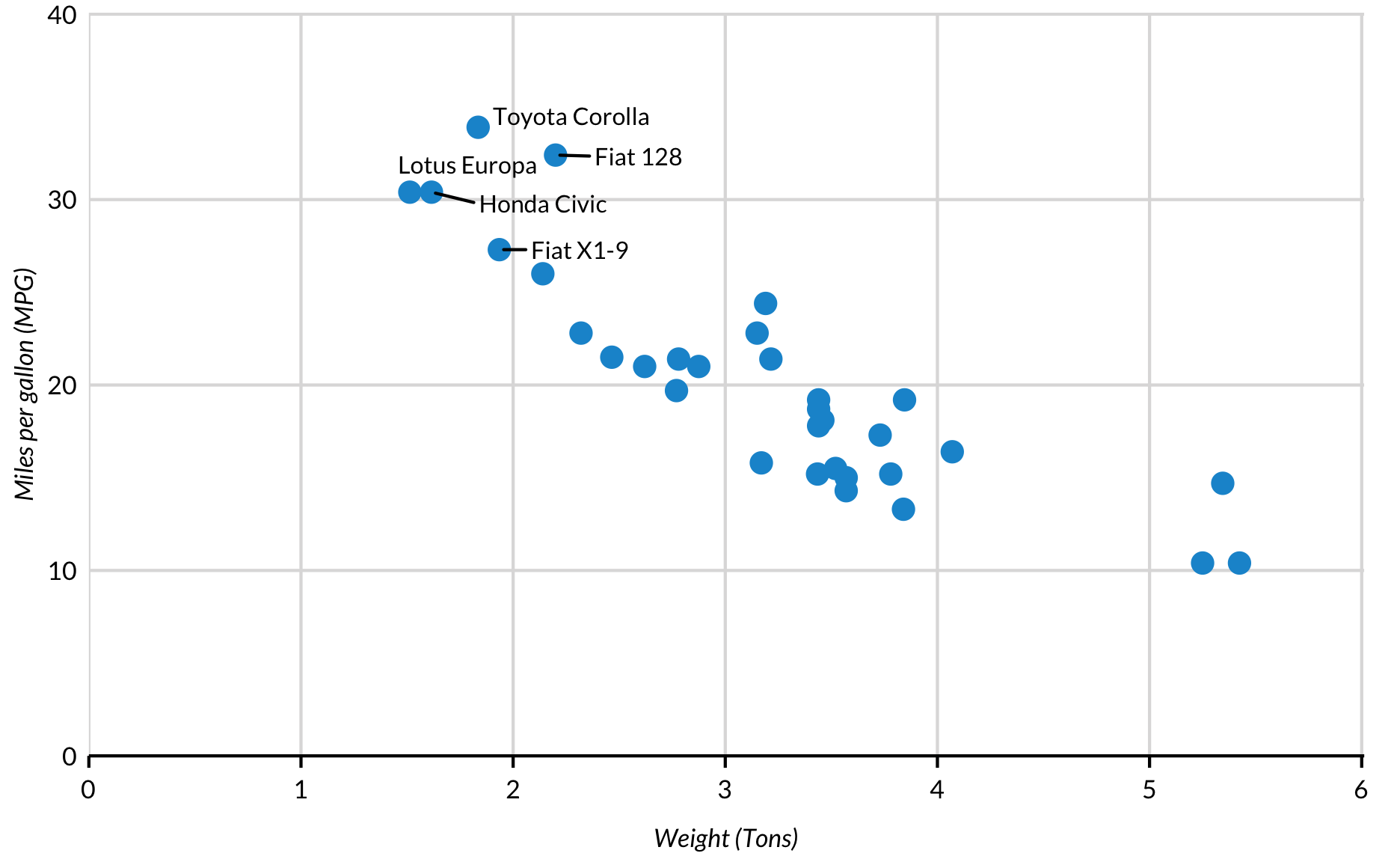
It can also be used to label points in a scatter plot.
It’s rarely useful to label every point in a scatter plot. Use filter() to create a second data set that is subsetted and pass it into the labelling function.
Text too often overlaps with other text or geoms when using geom_text(). library(ggrepel) is a library(ggplot2) add-on that automatically positions text so it doesn’t overlap with geoms or other text. To add this functionality, install and load library(ggrepel) and then use geom_text_repel() with the same syntax as geom_text().
Geoms can be layered in ggplot2. This is useful for design and analysis.
It is often useful to add points to line plots with a small number of values across the x-axis. This example from R for Data Science shows how changing the line to grey can be appealing.
Design
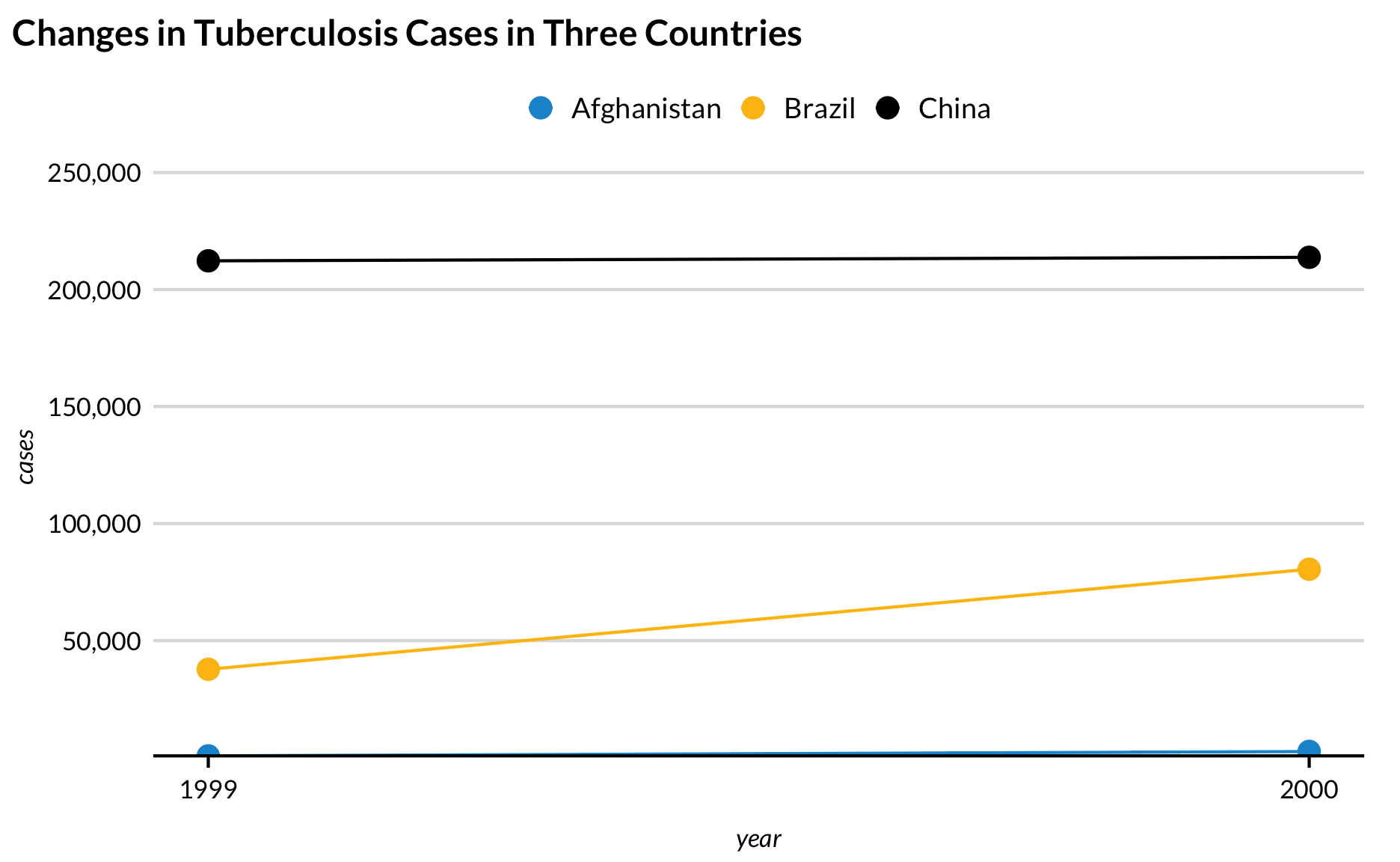
Before
table1 %>%ggplot(aes(x = year, y = cases)) +geom_line(aes(color = country)) +geom_point(aes(color = country)) +scale_y_continuous(expand =expansion(mult =c(0, 0.2)), labels = scales::comma) +scale_x_continuous(breaks =c(1999, 2000)) +labs(title ="Changes in Tuberculosis Cases in Three Countries")
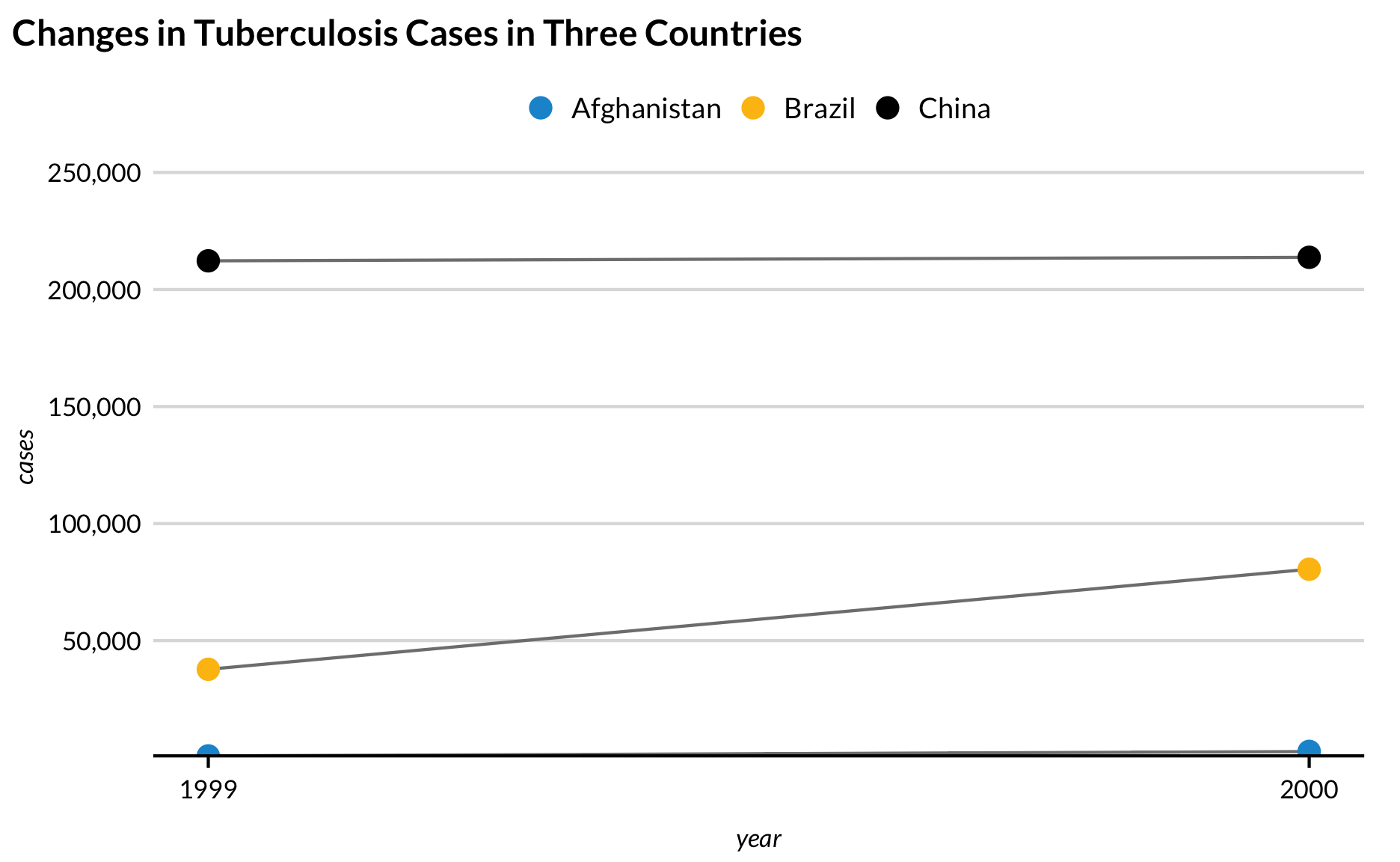
After
table1 %>%ggplot(aes(year, cases)) +geom_line(aes(group = country), color ="grey50") +geom_point(aes(color = country)) +scale_y_continuous(expand =expansion(mult =c(0, 0.2)), labels = scales::comma) +scale_x_continuous(breaks =c(1999, 2000)) +labs(title ="Changes in Tuberculosis Cases in Three Countries")
ggsave() exports ggplot2 plots. The function can be used in two ways. If plot = isn’t specified in the function call, then ggsave() automatically saves the plot that was last displayed in the Viewer window. Second, if plot = is specified, then ggsave() saves the specified plot. ggsave() guesses the type of graphics device to use in export (.png, .pdf, .svg, etc.) from the file extension in the filename.
Exported plots rarely look identical to the plots that show up in the Viewer window in RStudio because the overall size and aspect ratio of the Viewer is often different than the defaults for ggsave(). Specific sizes, aspect ratios, and resolutions can be controlled with arguments in ggsave(). RStudio has a useful cheatsheet called “How Big is Your Graph?” that should help with choosing the best size, aspect ratio, and resolution.
Fonts are not embedded in PDFs by default. To embed fonts in PDFs, include device = cairo_pdf in ggsave().
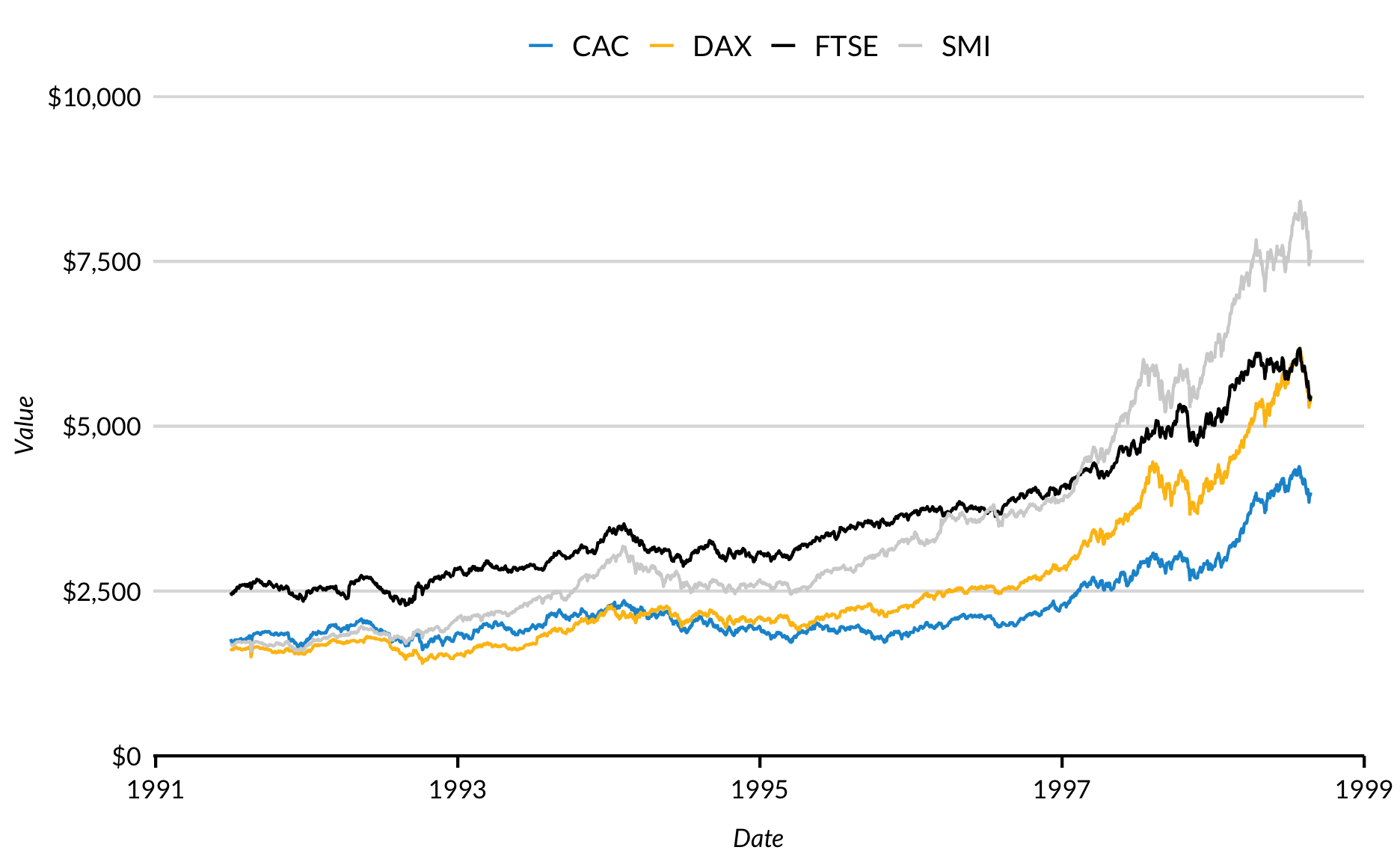
We can make any of the previous plots interactive with the powerful and easy plotly library. All we have to do is wrap a ggplot object in the ggplotly function. Note: You can’t add ggplotly to the end of a ggplot object, but have to actually save the ggplot as a variable and then wrap that in the function call as shown below.
You can customize the tooltip text by adding a value to text in aes() and then specifying tooltip = "text" in the ggplotly call.
library(plotly)stock_plot <-as_tibble(EuStockMarkets) %>%mutate(date =time(EuStockMarkets)) %>%gather(key ="key", value ="value", -date) %>%ggplot(mapping =aes(x = date, y = value, color = key,# sometimes ggplotly messes with line charts,# adding a group value usually helps with thatgroup = key,# customize the tooltip with the text aestext =paste0("Value: ", round(value, 2), "<br>","Date: ", round(date, 3), "<br>","Key: ", key)) ) +geom_line() +scale_x_continuous(expand =expansion(mult =c(0.002, 0)), limits =c(1991, 1999), breaks =c(1991, 1993, 1995, 1997, 1999)) +scale_y_continuous(expand =expansion(mult =c(0, 0.002)), breaks =0:4*2500,labels = scales::dollar, limits =c(0, 10000)) +labs(x ="Date",y ="Value")# make interactive with gggplotly# Uncomment pipe to hide the interative toolbar in the top right ggplotly(stock_plot, tooltip ="text") # %>% config(displayModeBar = FALSE)
urbnthemes
Overview
urbnthemes is a set of tools for creating Urban Institute-themed plots and maps in R. The package extends ggplot2 with print and map themes as well as tools that make plotting easier at the Urban Institute. urbnthemes replaces the urban_R_theme.
Always load library(urbnthemes) after library(ggplot2) or library(tidyverse).
Usage
Use set_urbn_defaults(style = "print") to set the default styles. scatter_grid(), remove_ticks(), add_axis(), and remove_axis() can all be used to improve graphics.
Sometimes it’s important to horizontally add the y-axis title above the plot. urbn_y_title() can be sued for this task. The following example goes one step further and adds the title between the legend and the plot.
urbnthemes contains many quick-access color palettes from the Urban Institute Data Visualization Style Guide. These palettes can be used to quickly overwrite default color palettes from urbnthemes.
palette_urbn_main is the eight color discrete palette of the Urban Institute with cyan, yellow, black, gray, magenta, green, space gray, and red.
palette_urbn_diverging is an eight color diverging palette.
palette_urbn_quintile is a five color blue palette that is good for quintiles.
palette_urbn_politics is a two color palette with blue for Democrats and red for Republicans.
There are seven palettes that are continuous palettes of the seven unique colors in the discrete Urban Institute color palette:
library(urbnthemes) contains four functions that are helpful with managing font instalations:
lato_test()
lato_install()
fontawesome_test()
fontawesome_install()
Bibliography and Session Information
Note: Examples present in this document by Aaron Williams were created during personal time.
Bob Rudis and Dave Gandy (2017). waffle: Create Waffle Chart Visualizations in R. R package version 0.7.0. https://CRAN.R-project.org/package=waffle
Chester Ismay and Jennifer Chunn (2017). fivethirtyeight: Data and Code Behind the Stories and Interactives at ‘FiveThirtyEight’. R package version 0.3.0. https://CRAN.R-project.org/package=fivethirtyeight
Hadley Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2009.
Hadley Wickham (2017). tidyverse: Easily Install and Load the ‘Tidyverse’. R package version 1.2.1. https://CRAN.R-project.org/package=tidyverse
Hadley Wickham (2017). forcats: Tools for Working with Categorical Variables (Factors). R package version 0.2.0. https://CRAN.R-project.org/package=forcats
Jennifer Bryan (2017). gapminder: Data from Gapminder. R package version 0.3.0. https://CRAN.R-project.org/package=gapminder
Kamil Slowikowski (2017). ggrepel: Repulsive Text and Label Geoms for ‘ggplot2’. R package version 0.7.0. https://CRAN.R-project.org/package=ggrepel
Max Kuhn (2017). AmesHousing: The Ames Iowa Housing Data. R package version 0.0.3. https://CRAN.R-project.org/package=AmesHousing
Peter Kampstra (2008). Beanplot: A Boxplot Alternative for Visual Comparison of Distributions, Journal of Statistical Software, 2008. https://www.jstatsoft.org/article/view/v028c01
R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
Winston Chang, (2014). extrafont: Tools for using fonts. R package version 0.17. https://CRAN.R-project.org/package=extrafont
Yihui Xie (2018). knitr: A General-Purpose Package for Dynamic Report Generation in R. R package version 1.19.