library( dplyr )
fpath <- "DATA-PREP/03-year-three/03-data-final/"
fname <- "YEAR-03-DATA-RESTRICTED-V05.csv"
df <- read.csv( paste0( fpath, fname ) )11 Preparing Public Use Files Y3
11.1 Load Restricted Data
11.2 Remove Identifying Variables
Remove all variables that:
- identify the organization
- identify individuals
- include long-form responses that might include details the compromise privacy
drop.these <-
c("ExternalReference", "ResponseID", "RecipientLastName", "RecipientFirstName",
"RecipientEmail", "Completion_Status", "FiscalYear", "FiscalYear_Other",
"Name_Primary", "Name_Secondary", "Q122", "Q122_3_TEXT", "Addr_StreetLocation",
"Addr_CityState", "Addr_ZIP",
"PrgSrvc_OthChng_Text", "Staff_Other_Text_2022", "Staff_Other_Text_2023",
"Staff_Other_Est_NA", "FndRaise_Text", "Finance_Rev_Oth_Text",
"FinanceChng_Text", "LeadershipChng_Oth_Text", "CEOrace_Text",
"BChairrace_Text", "Regulations_Other_TEXT", "CEOrace_Text_v2022",
"BChairrace_Text_v2022",
"ContactUpdateName", "ContactUpdateTitle",
"ContactUpdateEmail", "Comments" )
keep <-
c("PrgSrvc_IncrNum", "PrgSrvc_DcrsNum", "PrgSrvc_Suspend", "PrgSrvc_IncrSrvc",
"PrgSrvc_DcrsSrvc", "PrgSrvc_NewOffc", "PrgSrvc_ClsdOffc", "PrgSrvc_IncrArea",
"PrgSrvc_DcrsArea", "PrgSrvc_IncrFee", "PrgSrvc_DcrsFee", "PrgSrvc_ShiftOnline",
"PrgSrvc_AddOnline", "PrgSrvc_Oth", "PplSrv_NumServed", "PplSrv_NumWait",
"PplSrv_NumServed_NA_X", "PplSrv_NumWait_NA_X", "Dmnd_NxtYear",
"Staff_Fulltime_2022", "Staff_Parttime_2022", "Staff_Boardmmbr_2022",
"Staff_RegVlntr_2022", "Staff_EpsdVltnr_2022", "Staff_AmerVlntr_2022",
"Staff_PdCnslt_2022", "Staff_Other_Est_2022", "Staff_Fulltime_2023",
"Staff_Parttime_2023", "Staff_Boardmmbr_2023", "Staff_RegVlntr_2023",
"Staff_EpsdVltnr_2023", "Staff_AmerVlntr_2023", "Staff_PdCnslt_2023",
"Staff_Other_Est_2023", "Staff_Fulltime_NA", "Staff_Parttime_NA",
"Staff_Boardmmbr_NA", "Staff_RegVlntr_NA", "Staff_EpsdVltnr_NA",
"Staff_AmerVlntr_NA", "Staff_PdCnslt_NA", "Staff_Other_Text_NA",
"VolImportance", "DonImportance", "FndRaise_DvlpVirtual", "FndRaise_IncrExp",
"FndRaise_DcrsExp", "FndRaise_IncStaff", "FndRaise_DcrsStaff",
"FndRaise_IncrCnslt", "FndRaise_DcrsCnslt", "FndRaise_IncrVolntr",
"FndRaise_DcrsVolntr", "FndRaise_Othr", "FndRaise_MajGift_Amt",
"FndRaise_Overall_Chng", "FndRaise_Cashbelow250_Chng", "FndRaise_Cashabove250_Chng",
"FndRaise_MajGift_Chng", "FndRaise_Corp_Found_Grnt_Chng", "FndRaise_RstrGift_Chng",
"FndRaise_UnrstrGift_Chng", "FndRaise_DnrBlw250", "FndRaise_DnrAbv250",
"FndRaise_LocGvtGrnt_Seek", "FndRaise_StateGvtGrnt_Seek", "FndRaise_FedGvtGrnt_Seek",
"FndRaise_LocGvtCntrct_Seek", "FndRaise_StateGvtCntrct_Seek",
"FndRaise_FedGvtCntrct_Seek", "FndRaise_PFGrnt_Seek", "FndRaise_CFGrnt_Seek",
"FndRaise_DAF_Seek", "FndRaise_Corp_Found_Grnt_Seek", "FndRaise_UntdWy_Seek",
"FndRaise_CombFedCmpgn_Seek", "FndRaise_OthrGvngPrgrm_Seek",
"FndRaise_LocGvtGrnt_Rcv", "FndRaise_StateGvtGrnt_Rcv", "FndRaise_FedGvtGrnt_Rcv",
"FndRaise_LocGvtCntrct_Rcv", "FndRaise_StateGvtCntrct_Rcv", "FndRaise_FedGvtCntrct_Rcv",
"FndRaise_PFGrnt_Rcv", "FndRaise_CFGrnt_Rcv", "FndRaise_DAF_Rcv",
"FndRaise_Corp_Found_Grnt_Rcv", "FndRaise_UntdWy_Rcv", "FndRaise_CombFedCmpgn_Rcv",
"FndRaise_OthrGvngPrgrm_Rcv", "Finance_Rev_GovtMain", "Finance_Rev_Prtcpnt",
"Finance_Rev_IndvDon", "Finance_Rev_Gift", "Finance_Rev_Grnt",
"Finance_Rev_Spnsr", "Finance_Rev_Oth", "Reserves_Est", "Reserves_NA_X",
"CARES_Rcv", "CARES_Rcv_Est", "FinanceChng_Reserves", "FinanceChng_Borrow",
"FinanceChng_DcrsBnft", "FinanceChng_IncrBnft", "FinanceChng_IncrExp",
"FinanceChng_DcrsExp", "FinanceChng_Oth", "LeadershipChng_RetCEO",
"LeadershipChng_RsgnCEO", "LeadershipChng_TrmnCEO", "LeadershipChng_HireCEO",
"LeadershipChng_IntrmCEO", "LeadershipChng_ChngBC", "LeadershipChng_LostBoardMem",
"LeadershipChng_RplcBoardMem", "LeadershipChng_AddBoardMem",
"LeadershipChng_Oth", "CEOrace_AAPI", "CEOrace_Black", "CEOrace_Hisp",
"CEOrace_NativeAm", "CEOrace_White", "CEOrace_Oth", "CEOgender_Man",
"CEOgender_Woman", "CEOgender_Trans", "CEOgender_NB", "CEOgender_Oth",
"CEOgender_specify", "BChairrace_AAPI", "BChairrace_Black", "BChairrace_Hisp",
"BChairrace_NativeAm", "BChairrace_White", "BChairrace_Oth",
"BChairgender_Man", "BChairgender_Woman", "BChairgender_Trans",
"BChairgender_NB", "BChairgender_Oth", "BChairgender_specify",
"ExtAffairs_GenEd", "ExtAffairs_Media", "ExtAffairs_Advocacy",
"ExtAffairs_GovtRs", "ExtAffairs_DiscGovtGrnt", "ExtAffairs_InfoReq",
"ExtAffairs_Testify", "ExtAffairs_Lobby", "ExtAffairs_OrgPrtst",
"ExtAffairs_Mobilize", "ExtAffairs_Petition", "ExtAffairs_VoteReg",
"ExtAffairs_VoteEd", "Regulations", "Regulations_Local", "Regulations_State",
"Regulations_Federal", "Regulations_Info", "Regulations_Programming",
"Regulations_Forms", "Regulations_Requests", "Regulations_Advocate",
"Regulations_Research", "PrimaryConcern",
"StaffingPlans_HireDifferent", "StaffingPlans_HireSame", "StaffingPlans_Layoff",
"StaffingPlans_SlowDown", "StaffingPlans_SpeedUp", "StaffingPlans_LoseVoluntary",
"StaffingPlans_LoseRetirement", "StaffingPlans_Retrain", "StaffingPlans_NoChange",
"StaffingPlans_DK", "year3wt", "Staff_Fulltime_2023_imp",
"Staff_Parttime_2023_imp", "Staff_Boardmmbr_2023_imp", "Staff_RegVlntr_2023_imp",
"Staff_EpsdVltnr_2023_imp", "Staff_AmerVlntr_2023_imp", "Staff_PdCnslt_2023_imp",
"CEOrace_AAPI_v2022", "CEOrace_Black_v2022", "CEOrace_Hisp_v2022",
"CEOrace_NativeAm_v2022", "CEOrace_White_v2022", "CEOrace_Oth_v2022",
"CEOgender_Man_v2022", "CEOgender_Woman_v2022", "CEOgender_Trans_v2022",
"CEOgender_NB_v2022", "CEOgender_Oth_v2022", "CEOgender_specify_v2022",
"BChairrace_AAPI_v2022", "BChairrace_Black_v2022", "BChairrace_Hisp_v2022",
"BChairrace_NativeAm_v2022", "BChairrace_White_v2022", "BChairrace_Oth_v2022",
"BChairgender_Man_v2022", "BChairgender_Woman_v2022", "BChairgender_Trans_v2022",
"BChairgender_NB_v2022", "BChairgender_Oth_v2022", "BChairgender_specify_v2022",
"CEOrace_Bi", "BChairrace_Bi", "CEOrace", "BChairrace", "CEOgender",
"BChairgender")
df <- df[keep]11.3 Add Noise to Numeric Responses
Add noise to numeric responses that could possibly be compared with public records to identify the organization.
# identify numeric variables easily:
# names(df)[ (lapply(df,class) |> unlist()) != "character" ] |> dput()
financials <-
c("Staff_Fulltime_2022",
"Staff_Parttime_2022", "Staff_Boardmmbr_2022", "Staff_RegVlntr_2022",
"Staff_EpsdVltnr_2022", "Staff_AmerVlntr_2022", "Staff_PdCnslt_2022",
"Staff_Other_Est_2022", "Staff_Fulltime_2023", "Staff_Parttime_2023",
"Staff_Boardmmbr_2023", "Staff_RegVlntr_2023", "Staff_EpsdVltnr_2023",
"Staff_AmerVlntr_2023", "Staff_PdCnslt_2023", "Staff_Other_Est_2023",
"FndRaise_MajGift_Amt", "FndRaise_DnrBlw250", "FndRaise_DnrAbv250",
"Finance_Rev_GovtMain", "Finance_Rev_Prtcpnt", "Finance_Rev_IndvDon",
"Finance_Rev_Gift", "Finance_Rev_Grnt", "Finance_Rev_Spnsr",
"Finance_Rev_Oth", "Reserves_Est", "CARES_Rcv_Est",
"Staff_Fulltime_2023_imp", "Staff_Parttime_2023_imp", "Staff_Boardmmbr_2023_imp",
"Staff_RegVlntr_2023_imp", "Staff_EpsdVltnr_2023_imp", "Staff_AmerVlntr_2023_imp",
"Staff_PdCnslt_2023_imp", "CEOgender_specify_v2022")
add_noise <- function(x){
if( is.na(x) | is.nan(x) ){ return(NA) }
v <- x/20 # standard dev of 5% of base
x <- rnorm( n=1, mean=x, sd=v ) |> round(0)
return(x)
}
add_noise( 3000 )[1] 3092make_noise <- function(x){
x <- purrr::map_dbl( x, add_noise )
return(x)
}
df2 <- df # make a copy for comparison
df[financials] <- lapply( df[financials], make_noise )
max <- quantile( df$Finance_Rev_IndvDon, 0.9, na.rm=T )
plot( df$Finance_Rev_IndvDon, df2$Finance_Rev_IndvDon,
bty="n", pch=19, col=gray(0.5,0.5), cex=1.5,
xlim=c(0,max), ylim=c(0,max),
main="Inspect Noise" )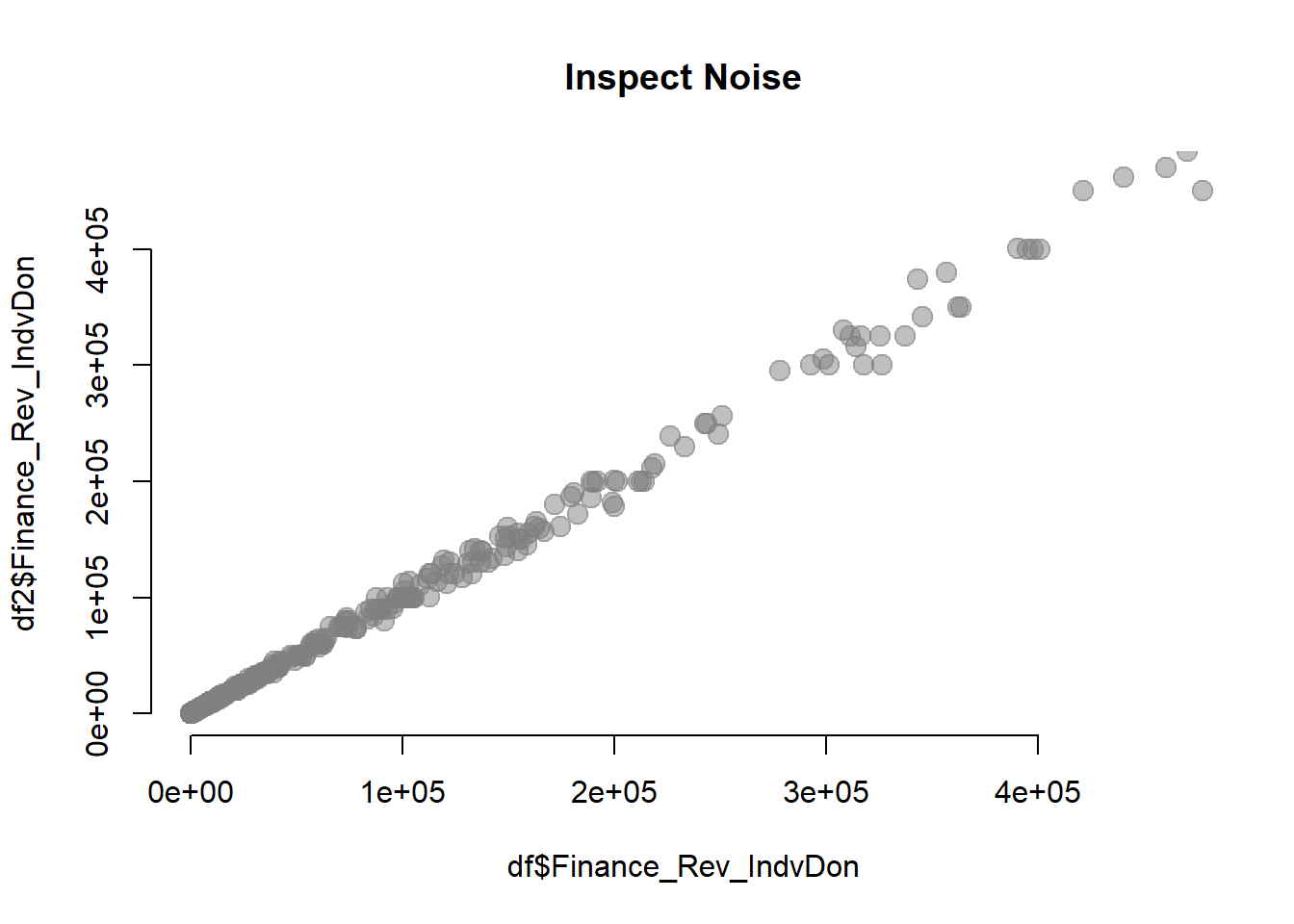
max <- quantile( df$Staff_Fulltime_2022, 0.9, na.rm=T )
plot( df$Staff_Fulltime_2022, df2$Staff_Fulltime_2022,
bty="n", pch=19, col=gray(0.5,0.5), cex=1.5,
xlim=c(0,max), ylim=c(0,max),
main="Inspect Noise" )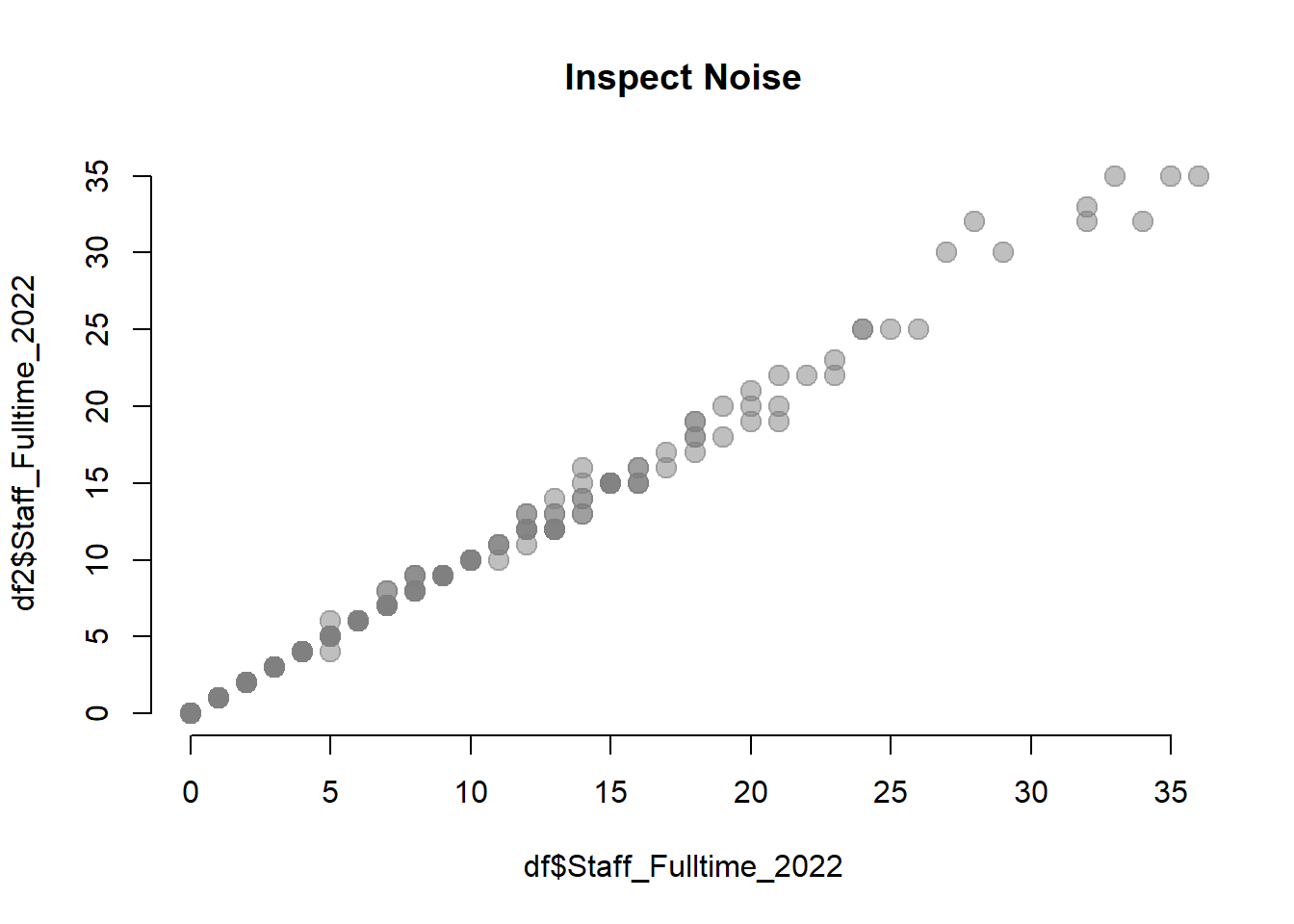
max <- quantile( df$Staff_Fulltime_2023, 0.9, na.rm=T )
plot( df$Staff_Fulltime_2023, df$Staff_Fulltime_2023_imp,
bty="n", pch=19, col=gray(0.5,0.5), cex=1.5,
xlim=c(0,max), ylim=c(0,max),
main="Inspect Noise" )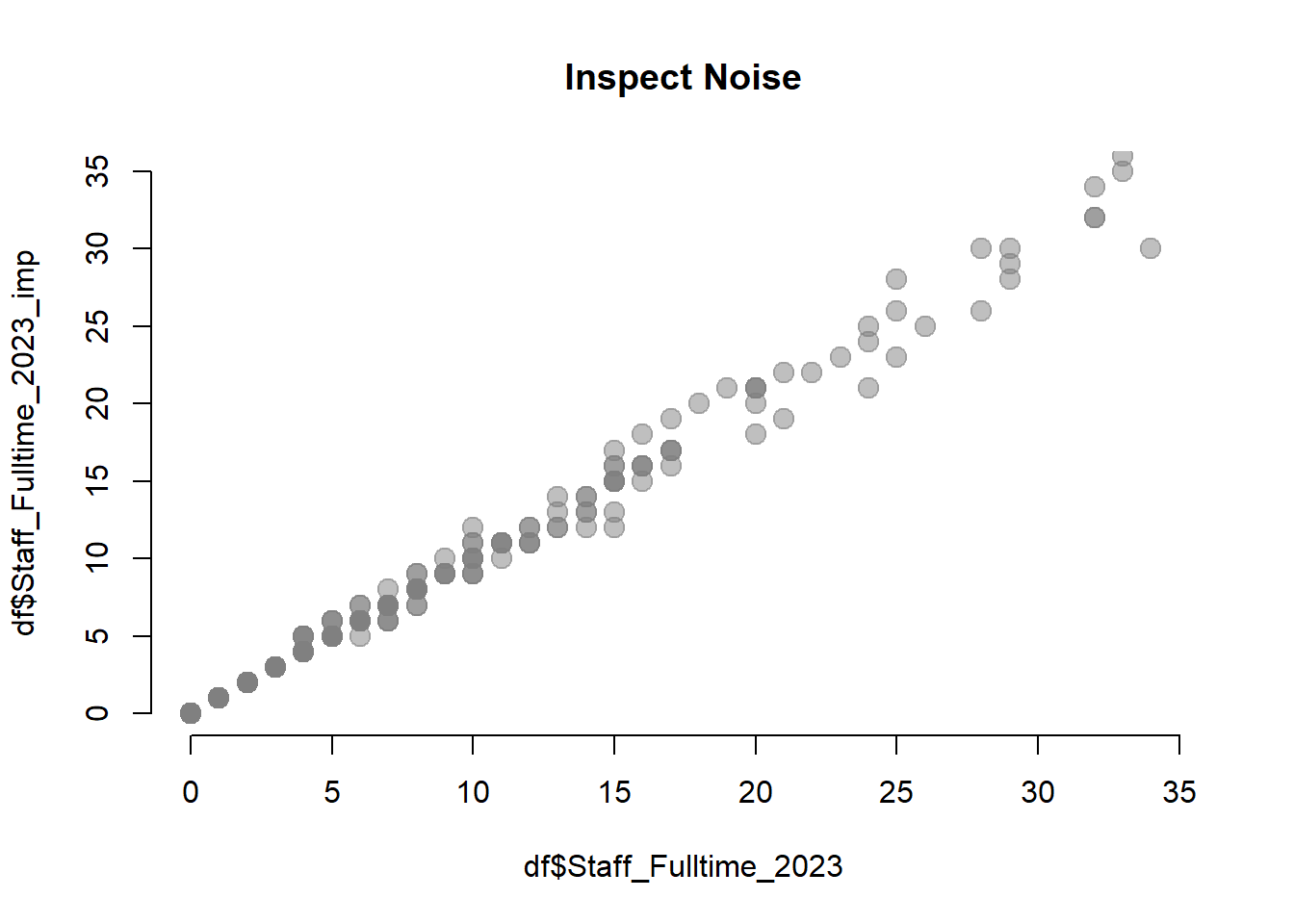
11.4 Save to File
fpath <- "DATA-PREP/03-year-three/03-data-final/"
fname <- "YEAR-03-DATA-PUF.csv"
write.csv( df, paste0( fpath, fname ), row.names=FALSE, na="" )